Forecasting Switzerland's Inflation Rate
Data Source: https://www.worldbank.org/en/research/brief/inflation-database
Notebook Content:
- Reading and Preprocessing Data.
- Explanatory Data Analysis.
- Statistical Analysis.
- ARIMA Model
- SARIMA Model.
- Backtesting.
import statsmodels.api as sm
from statsmodels.tsa.seasonal import seasonal_decompose
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.stattools import adfuller
import warnings
import matplotlib.dates as mdates
from pmdarima import auto_arima
from statsmodels.tsa.arima.model import ARIMA
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_squared_error
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Helper Functions:
def melt_dataframe_consumer_price_index(inflation_data, country, list_dates):
inflation_data = inflation_data[inflation_data["Country"] == country]
df_melted = pd.melt(
inflation_data,
id_vars=['Country Code',
'IMF Country Code',
'Country',
'Indicator Type',
'Series Name'],
value_vars=[year for year in list_dates],
var_name='year',
value_name='value'
)
df_melted.drop(columns=["Country Code", "IMF Country Code", "Country", "Indicator Type", "Series Name"], axis=1,
inplace=True)
return df_melted
def melt_dataframe_inflation_rate(inflation_data, country):
inflation_data = inflation_data[inflation_data["Country"] == country]
df_melted = pd.melt(
inflation_data,
id_vars=['Country Code',
'IMF Country Code',
'Country',
'Indicator Type',
'Series Name'],
value_vars=[year for year in range(1970, 2023)],
var_name='year',
value_name='value'
)
df_melted.drop(columns=["Country Code", "IMF Country Code", "Country", "Indicator Type", "Series Name"], axis=1,
inplace=True)
return df_melted
def get_country_data(inflation_data, country, list_dates):
country_sample = melt_dataframe_consumer_price_index(inflation_data, country, list_dates)
country_sample.rename(columns={"year": "YearMonth", "value": "HCPI"}, inplace=True)
country_sample['YearMonth'] = country_sample['YearMonth'].astype(str)
country_sample['YearMonth'] = country_sample['YearMonth'].str[:4] + '-' + country_sample['YearMonth'].str[4:]
return country_sample
def get_country_data_annualy(inflation_data, country, list_dates):
country_sample = melt_dataframe_consumer_price_index(inflation_data, country, list_dates)
return country_sample
def get_monthly_inflation_from_CPI(country_sample):
country_sample['Monthly Inflation Rate'] = ((country_sample['HCPI'] - country_sample['HCPI'].shift(1)) /
country_sample['HCPI'].shift(1)) * 100
return country_sample
def get_yearly_inflation_from_monthly(country_sample):
df_new_format = pd.DataFrame(country_sample)
df_new_format['YearMonth'] = pd.to_datetime(df_new_format['YearMonth'])
yearly_avg_cpi_datetime = df_new_format.groupby(df_new_format['YearMonth'].dt.year).mean()['HCPI']
# Calculate the yearly inflation rate using the yearly average CPI
yearly_avg_inflation_rate_datetime = ((yearly_avg_cpi_datetime - yearly_avg_cpi_datetime.shift(
1)) / yearly_avg_cpi_datetime.shift(1)) * 100
yearly_avg_inflation_datetime = yearly_avg_inflation_rate_datetime.reset_index()
yearly_avg_inflation_datetime.columns = ['Year', 'Yearly Inflation Rate (Avg)']
return yearly_avg_inflation_datetime
def adf_test(series):
result = adfuller(series, regression='c', autolag='AIC')
print('======= Augmented Dickey-Fuller Test Results =======\n')
print('1. ADF Test Statistic: {:.6f}'.format(result[0]))
print('2. P-value: {:.6f}'.format(result[1]))
print('3. Used Lags: {}'.format(result[2]))
print('4. Used Observations: {}'.format(result[3]))
print('5. Critical Values:')
for key, value in result[4].items():
print('\t{}: {:.6f}'.format(key, value))
critical_value = result[4]['5%']
if (result[1] <= 0.05) and (result[0] < critical_value):
print('\nStrong evidence against the null hypothesis (H0), reject the null hypothesis.\
Data has no unit root and is stationary.')
else:
print('\nWeak evidence against null hypothesis, time series has a unit root, indicating it is non-stationary.')
return
def series_transformation(series):
fig = plt.figure(figsize=(16, 4))
ax1 = fig.add_subplot(1, 3, 1)
ax1.set_title('Transformed Series')
ax1.plot(series)
ax1.plot(series.rolling(window=12).mean(), color='crimson')
ax1.plot(series.rolling(window=12).std(), color='black')
ax2 = fig.add_subplot(1, 3, 2)
plot_acf(series.dropna(), ax=ax2, lags=50, title='Autocorrelation')
# plot 95% confidence intervals
plt.axhline(y=-1.96 / np.sqrt(len(series)), linestyle='--', color='gray')
plt.axhline(y=1.96 / np.sqrt(len(series)), linestyle='--', color='gray')
plt.xlabel('lags')
ax3 = fig.add_subplot(1, 3, 3)
plot_pacf(series.dropna(), ax=ax3, lags=50, title='Partial Autocorrelation')
plt.axhline(y=-1.96 / np.sqrt(len(series)), linestyle='--', color='gray')
plt.axhline(y=1.96 / np.sqrt(len(series)), linestyle='--', color='gray')
plt.xlabel('lags')
plt.show()
# ADF test
result = adfuller(series.dropna(), regression='c', autolag='AIC')
critical_value = result[4]['5%']
if (result[1] <= 0.05) and (result[0] < critical_value):
print('P-value = {:.6f}, the series is likely stationary.'.format(result[1]))
else:
print('P-value = {:.6f}, the series is likely non-stationary.'.format(result[1]))
return
def find_best_arima_params(series, max_p=5, max_d=5, max_q=5, verbose=True):
warnings.filterwarnings("ignore") # Ignore warning messages for clarity
best_aic = float('inf')
best_params = None
for p in range(max_p + 1):
for d in range(max_d + 1):
for q in range(max_q + 1):
try:
model = ARIMA(series, order=(p, d, q))
results = model.fit()
if results.aic < best_aic:
best_aic = results.aic
best_params = (p, d, q)
except Exception as e:
if verbose:
print(f"ARIMA({p},{d},{q}) - AIC: N/A - Error: {str(e)}")
continue
if verbose:
print(f"Best ARIMA{best_params} model - AIC: {best_aic}")
return best_params
def find_best_arima_params_metric(series, max_p=5, max_d=5, max_q=5, verbose=True):
warnings.filterwarnings("ignore") # Ignore warning messages for clarity
best_mse = float('inf')
best_params = None
for p in range(max_p + 1):
for d in range(max_d + 1):
for q in range(max_q + 1):
try:
model = ARIMA(series, order=(p, d, q))
results = model.fit()
predicted = results.predict()
mse = ((series[d:] - predicted) ** 2).mean() # Calculating MSE for in-sample predictions
if mse < best_mse:
best_mse = mse
best_params = (p, d, q)
except Exception as e:
if verbose:
print(f"ARIMA({p},{d},{q}) - MSE: N/A - Error: {str(e)}")
continue
if verbose:
print(f"Best ARIMA{best_params} model - MSE: {best_mse}")
return best_params
def visualize_cpi(data):
plt.figure(figsize=(20, 6))
sns.lineplot(x='YearMonth', y='HCPI', data=data)
plt.title('Headline Consumer Price Index over Time', fontsize=20)
plt.xlabel('YearMonth', fontsize=15)
plt.ylabel('Headline CPI', fontsize=15)
num_ticks = 40
ticks = data['YearMonth'].unique()
plt.xticks(ticks[::len(ticks) // num_ticks], rotation=45, fontsize=13)
plt.yticks(fontsize=13)
plt.tight_layout()
plt.show()
def format_year(year_float):
if year_float.is_integer():
return str(int(year_float))
else:
return str(year_float)
def custom_round(val):
if val == int(val):
return int(val)
else:
return round(val, 1)
Reading and Pre-processing Data:
data_path = "data/Inflation-data.xlsx"
inflation_excel_file = pd.ExcelFile(data_path)
inflation_excel_file.sheet_names
['Intro',
'top',
'hcpi_m',
'hcpi_q',
'hcpi_a',
'ecpi_m',
'ecpi_q',
'ecpi_a',
'fcpi_m',
'fcpi_q',
'fcpi_a',
'ccpi_m',
'ccpi_q',
'ccpi_a',
'ppi_m',
'ppi_q',
'ppi_a',
'def_q',
'def_a',
'ccpi_m_e',
'ccpi_q_e',
'ccpi_a_e',
'hcpi_q_t',
'hcpi_q_c',
'Aggregate']
overall_inflation = pd.read_excel(data_path,sheet_name="top")
overall_inflation.describe()
| Unnamed: 0 | Unnamed: 1 | Unnamed: 2 | |
|---|---|---|---|
| count | 0.0 | 0.0 | 0.0 |
| mean | NaN | NaN | NaN |
| std | NaN | NaN | NaN |
| min | NaN | NaN | NaN |
| 25% | NaN | NaN | NaN |
| 50% | NaN | NaN | NaN |
| 75% | NaN | NaN | NaN |
| max | NaN | NaN | NaN |
inflation_data = pd.read_excel(data_path,sheet_name="hcpi_m")
inflation_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 188 entries, 0 to 187
Columns: 648 entries, Country Code to Note
dtypes: float64(636), object(12)
memory usage: 951.9+ KB
data_columns = inflation_data.columns.tolist()
to_remove = ['Country Code',
'IMF Country Code',
'Country',
'Indicator Type',
'Series Name',
'Unnamed: 644',
'Data source',
'Base date',
'Note']
list_dates = [item for item in data_columns if item not in to_remove]
Switzerland_sample = get_country_data(inflation_data,"Switzerland",list_dates)
Switzerland_sample.head(20)
| YearMonth | HCPI | |
|---|---|---|
| 0 | 1970-01 | 33.4 |
| 1 | 1970-02 | 33.4 |
| 2 | 1970-03 | 33.4 |
| 3 | 1970-04 | 33.4 |
| 4 | 1970-05 | 33.7 |
| 5 | 1970-06 | 33.9 |
| 6 | 1970-07 | 34.0 |
| 7 | 1970-08 | 34.1 |
| 8 | 1970-09 | 34.3 |
| 9 | 1970-10 | 34.5 |
| 10 | 1970-11 | 34.9 |
| 11 | 1970-12 | 35.1 |
| 12 | 1971-01 | 35.3 |
| 13 | 1971-02 | 35.4 |
| 14 | 1971-03 | 35.7 |
| 15 | 1971-04 | 35.7 |
| 16 | 1971-05 | 36.1 |
| 17 | 1971-06 | 36.1 |
| 18 | [..](..)1971-07 | 36.3 |
| 19 | 1971-08 | 36.3 |
visualize_cpi(Switzerland_sample)
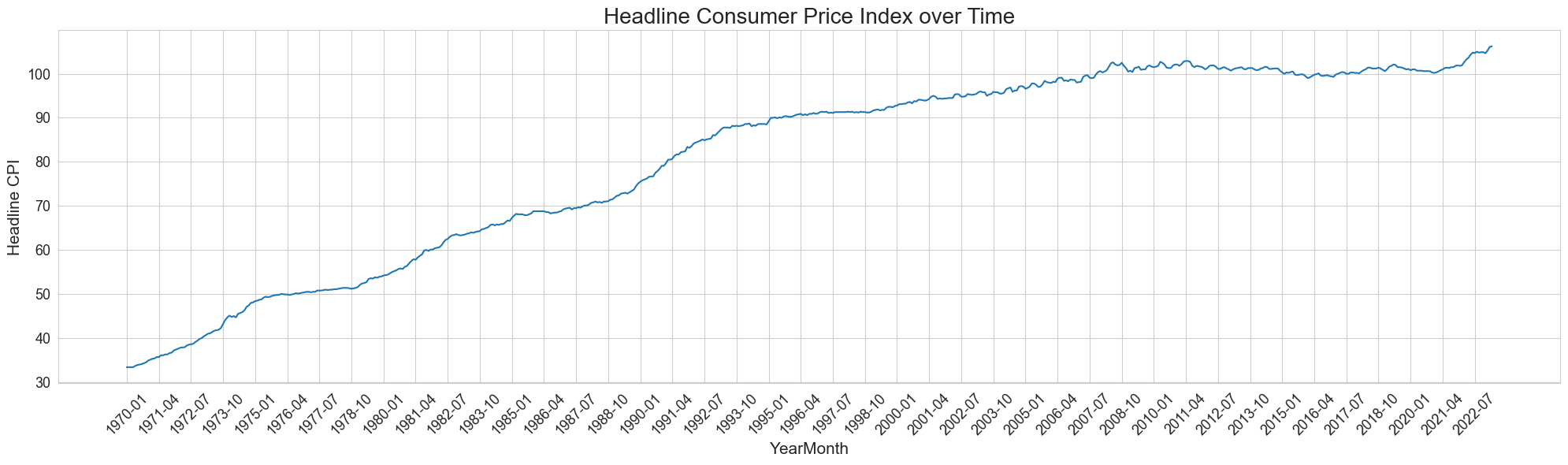
Switzerland_sample = get_monthly_inflation_from_CPI(Switzerland_sample)
Switzerland_sample.head(20)
| YearMonth | HCPI | Monthly Inflation Rate | |
|---|---|---|---|
| 0 | 1970-01 | 33.4 | NaN |
| 1 | 1970-02 | 33.4 | 0.0 |
| 2 | 1970-03 | 33.4 | 0.0 |
| 3 | 1970-04 | 33.4 | 0.0 |
| 4 | 1970-05 | 33.7 | 0.898204 |
| 5 | 1970-06 | 33.9 | 0.593472 |
| 6 | 1970-07 | 34.0 | 0.294985 |
| 7 | 1970-08 | 34.1 | 0.294118 |
| 8 | 1970-09 | 34.3 | 0.58651 |
| 9 | 1970-10 | 34.5 | 0.58309 |
| 10 | 1970-11 | 34.9 | 1.15942 |
| 11 | 1970-12 | 35.1 | 0.573066 |
| 12 | 1971-01 | 35.3 | 0.569801 |
| 13 | 1971-02 | 35.4 | 0.283286 |
| 14 | 1971-03 | 35.7 | 0.847458 |
| 15 | 1971-04 | 35.7 | 0.0 |
| 16 | 1971-05 | 36.1 | 1.120448 |
| 17 | 1971-06 | 36.1 | 0.0 |
| 18 | 1971-07 | 36.3 | 0.554017 |
| 19 | 1971-08 | 36.3 | 0.0 |
EDA and Visualizations:
Switzerland_sample['YearMonth'] = Switzerland_sample['YearMonth'].astype(str)
selected_years = Switzerland_sample['YearMonth'].unique()[::11]
plt.figure(figsize=(20, 8))
sns.lineplot(data=Switzerland_sample, x='YearMonth', y='Monthly Inflation Rate', marker='o')
plt.title('Monthly Inflation Rate for Switzerland (1970 - 2023)', fontsize=18)
plt.ylabel('Monthly Inflation Rate (%)', fontsize=16)
plt.yticks(fontsize=14)
plt.xlabel('YearMonth', fontsize=16)
plt.xticks(selected_years)
plt.grid(True)
plt.tight_layout()
plt.xticks(rotation=45)
plt.show()
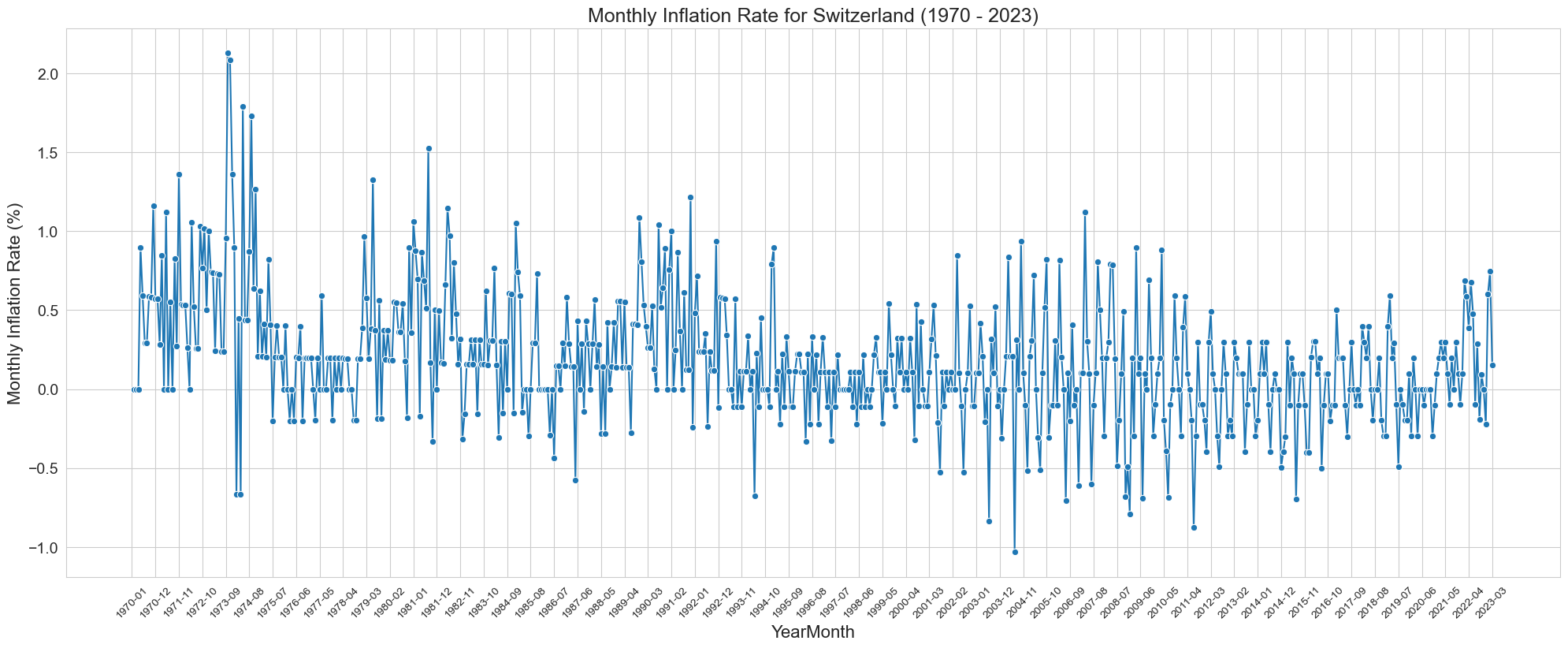
Switzerland_sample['YearMonth'] = Switzerland_sample['YearMonth'].astype(str)
selected_years = Switzerland_sample['YearMonth'].unique()[::12]
rolling_mean = Switzerland_sample['Monthly Inflation Rate'].rolling(window=12).mean()
rolling_std = Switzerland_sample['Monthly Inflation Rate'].rolling(window=12).std()
plt.figure(figsize=(22, 8))
sns.lineplot(data=Switzerland_sample, x='YearMonth', y='Monthly Inflation Rate', marker='o', label='Inflation Rate')
sns.lineplot(data=Switzerland_sample, x='YearMonth', y=rolling_mean, color='r', label='Rolling Mean')
sns.lineplot(data=Switzerland_sample, x='YearMonth', y=rolling_std, color='g', label='Rolling Std')
plt.title('Inflation Rate for Switzerland with Rolling Mean and Std', fontsize=20)
plt.xlabel('Year', fontsize=18)
plt.ylabel('Value', fontsize=18)
plt.xticks(selected_years, fontsize=16)
plt.yticks(fontsize=12)
plt.grid(True)
plt.axhline(0, color='red', linewidth=1)
plt.tight_layout()
plt.xticks(rotation=45)
plt.legend()
plt.show()
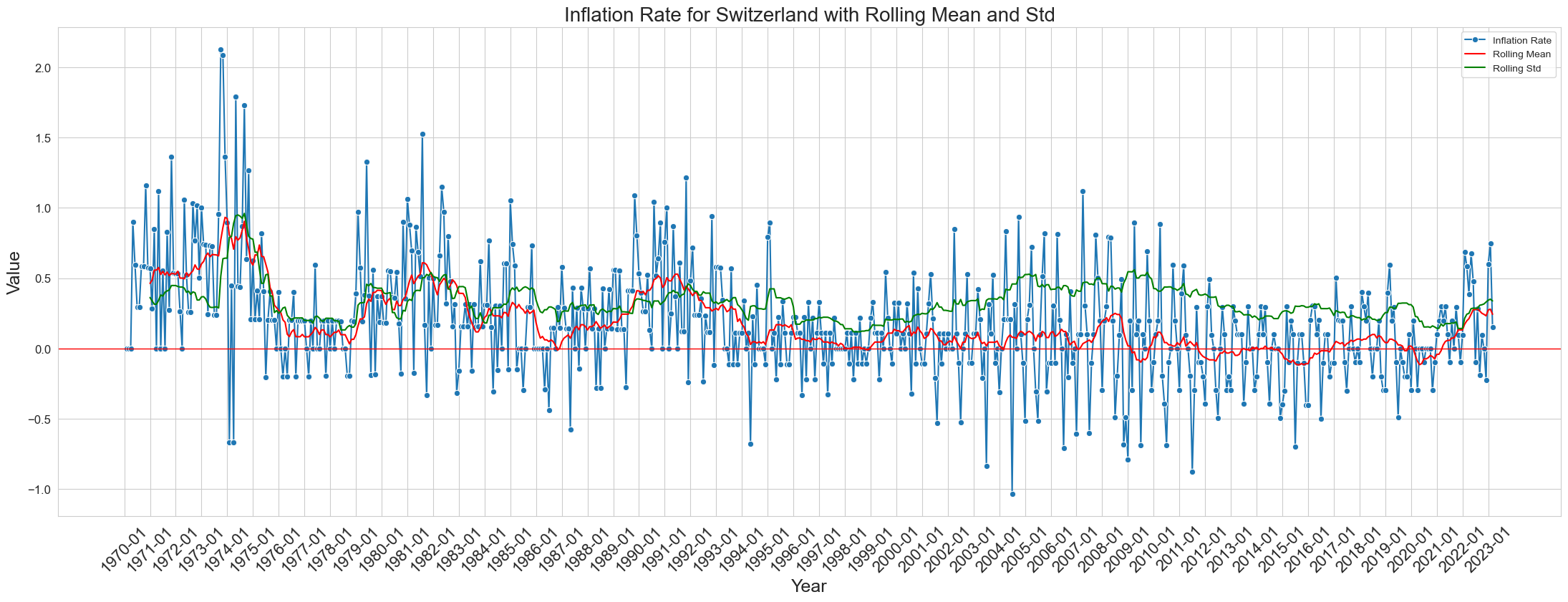
yearly_inflation = get_yearly_inflation_from_monthly(Switzerland_sample)
yearly_inflation.dropna(inplace=True)
yearly_inflation['Year'] = yearly_inflation['Year'].astype(str)
selected_years = yearly_inflation['Year'].unique()[::2]
plt.figure(figsize=(22, 8))
sns.lineplot(data=yearly_inflation, x='Year', y='Yearly Inflation Rate (Avg)', marker='o')
plt.title('Inflation Rate for Switzerland', fontsize=20)
plt.xlabel('Year', fontsize=18)
plt.ylabel('Inflation Rate', fontsize=18)
plt.xticks(selected_years, fontsize=16)
plt.yticks(fontsize=16)
plt.yticks(np.arange(min(yearly_inflation['Yearly Inflation Rate (Avg)']), max(yearly_inflation['Yearly Inflation Rate (Avg)'])+1, 2), fontsize=14)
plt.grid(True)
for idx, row in yearly_inflation.iterrows():
plt.annotate(f"{row['Yearly Inflation Rate (Avg)']:.2f}%",
(row['Year'], row['Yearly Inflation Rate (Avg)']),
textcoords="offset points", xytext=(0,5), ha='center',
fontsize=10)
plt.axhline(0, color='red',
linewidth=1)
plt.tight_layout()
plt.xticks(rotation=45)
plt.show()
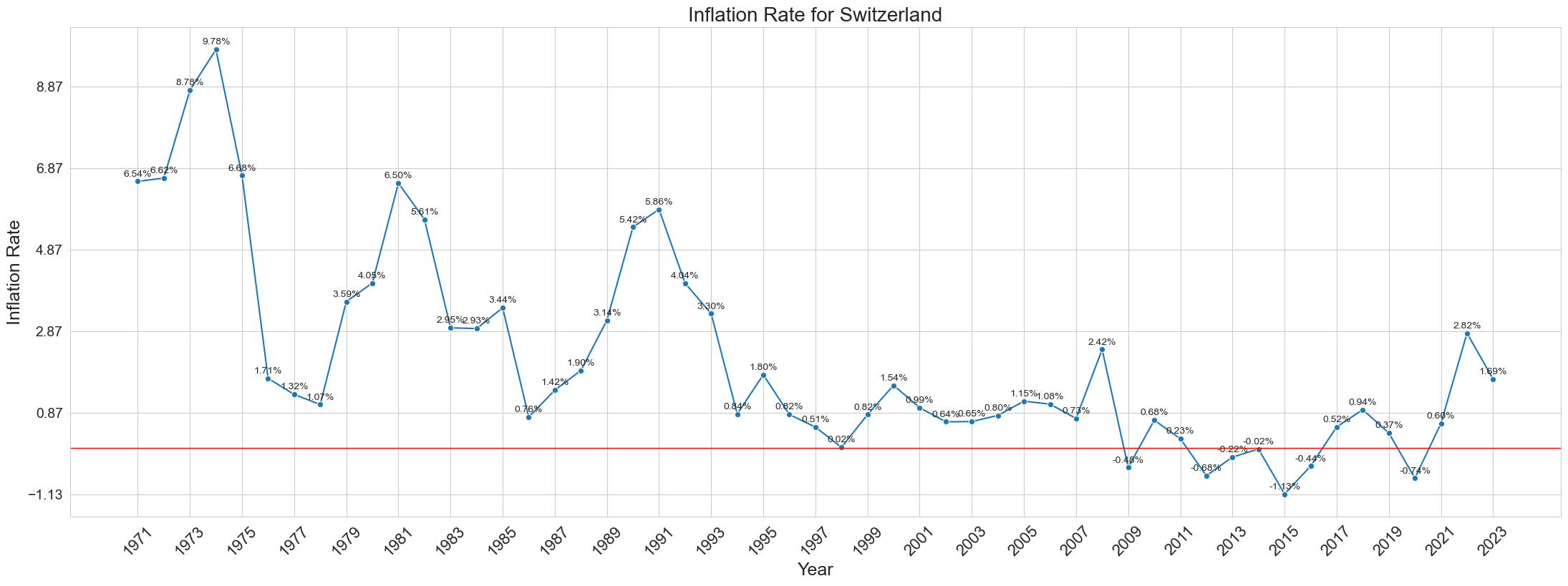
Observations:
- No clear trend or seasonality is shown from Switzerland’s yearly inflation rates.
- Inflation rates go below zero from 2007 to 2015 with an evidence spike or upward trend from 2019 to 2021.
- Overall, the series exhibits stability for each 5 years.
Statistical Analysis:
yearly_inflation['Year'] = yearly_inflation['Year'].astype(str)
selected_years = yearly_inflation['Year'].unique()[::2]
rolling_mean = yearly_inflation['Yearly Inflation Rate (Avg)'].rolling(window=2).mean()
rolling_std = yearly_inflation['Yearly Inflation Rate (Avg)'].rolling(window=2).std()
plt.figure(figsize=(22, 8))
sns.lineplot(data=yearly_inflation, x='Year', y='Yearly Inflation Rate (Avg)', marker='o', label='Inflation Rate')
sns.lineplot(data=yearly_inflation, x='Year', y=rolling_mean, color='r', label='Rolling Mean')
sns.lineplot(data=yearly_inflation, x='Year', y=rolling_std, color='g', label='Rolling Std')
plt.title('Inflation Rate for Switzerland with Rolling Mean and Std', fontsize=20)
plt.xlabel('Year', fontsize=18)
plt.ylabel('Value', fontsize=18)
plt.xticks(selected_years, fontsize=16)
plt.yticks(fontsize=12)
plt.grid(True)
plt.axhline(0, color='red', linewidth=1)
plt.tight_layout()
plt.xticks(rotation=45)
plt.legend(fontsize='large')
plt.show()
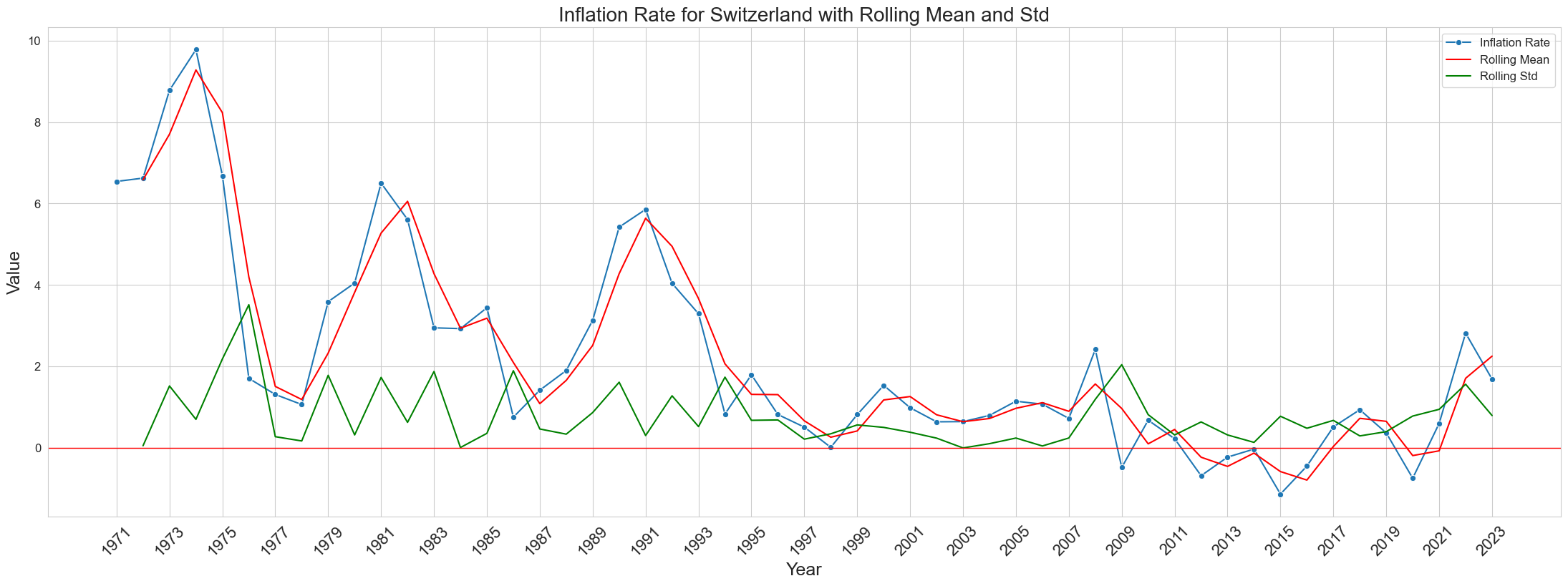
Observations:
- The moving average of 12 months fits the series well over the years.
- Moving std is unable to capture the sudden upward and downward trend between in the series.
Switzerland_sample.dropna(inplace=True)
Switzerland_sample['Date'] = pd.to_datetime(Switzerland_sample['YearMonth'])
Switzerland_sample.set_index('Date', inplace=True)
decomposition = seasonal_decompose(Switzerland_sample['Monthly Inflation Rate'], model='additive')
plt.figure(figsize=(20, 12))
# Original
plt.subplot(4, 1, 1)
plt.plot(Switzerland_sample['Monthly Inflation Rate'], label='Original')
plt.legend(loc='upper left')
plt.title('Original Time Series')
# Trend
plt.subplot(4, 1, 2)
plt.plot(decomposition.trend, label='Trend')
plt.legend(loc='upper left')
plt.title('Trend')
# Seasonal
plt.subplot(4, 1, 3)
plt.plot(decomposition.seasonal, label='Seasonal')
plt.legend(loc='upper left')
plt.title('Seasonal')
# Residual
plt.subplot(4, 1, 4)
plt.plot(decomposition.resid, label='Residual')
plt.legend(loc='upper left')
plt.title('Residual')
plt.tight_layout()
plt.show()
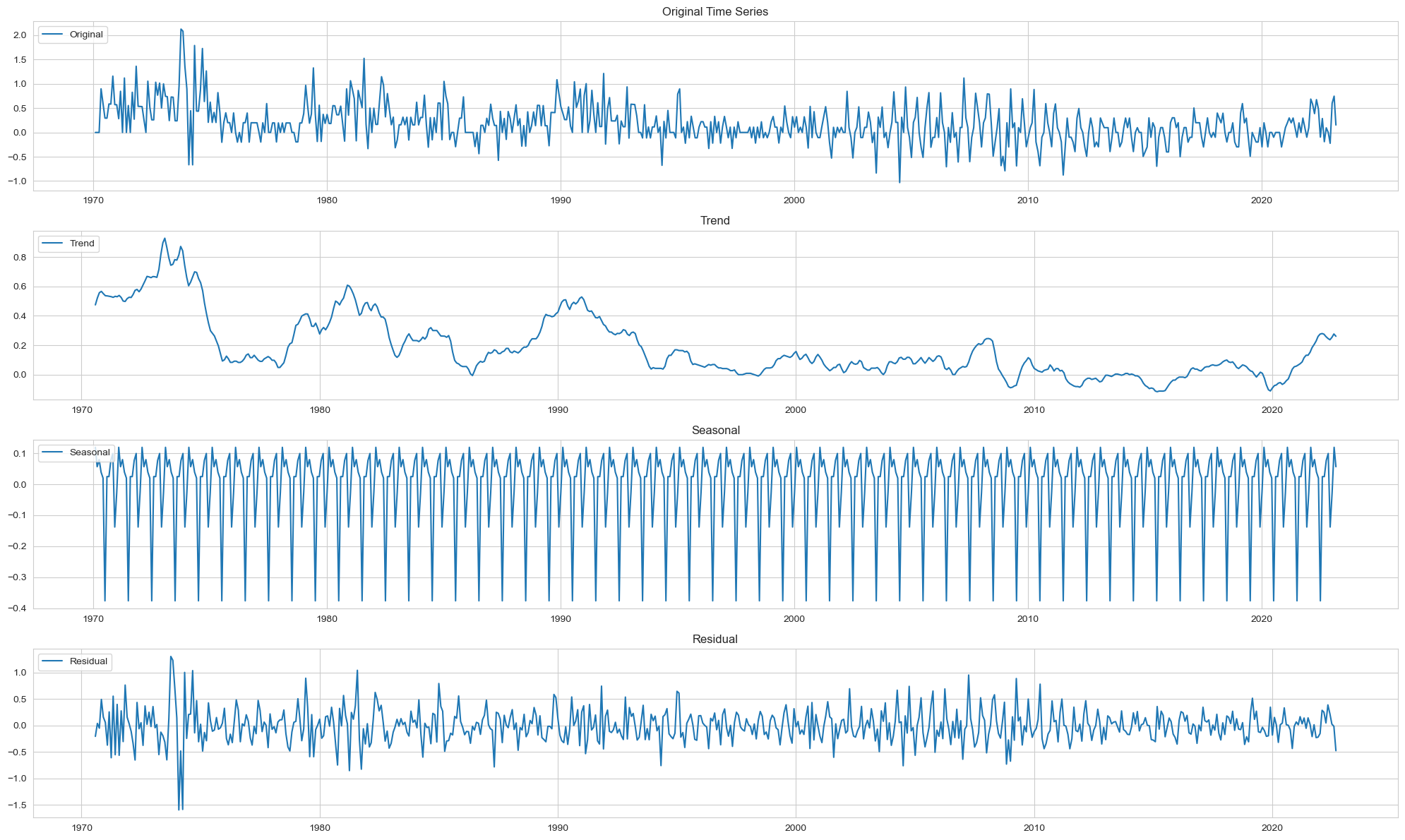
Observations:
- We can see no clear observation of trends in the series from 1970 till 1990.
- Slight downward trend from 1990 to 2000.
- A seasonable trend is clearly observable from the above graph.
- Residual shows a very stable series with constant means across the years.
adf_test(Switzerland_sample["Monthly Inflation Rate"])
======= Augmented Dickey-Fuller Test Results =======
1. ADF Test Statistic: -2.759119
2. P-value: 0.064355
3. Used Lags: 12
4. Used Observations: 625
5. Critical Values:
1%: -3.440856
5%: -2.866175
10%: -2.569239
Weak evidence against null hypothesis, time series has a unit root, indicating it is non-stationary.
series_transformation(Switzerland_sample["Monthly Inflation Rate"])
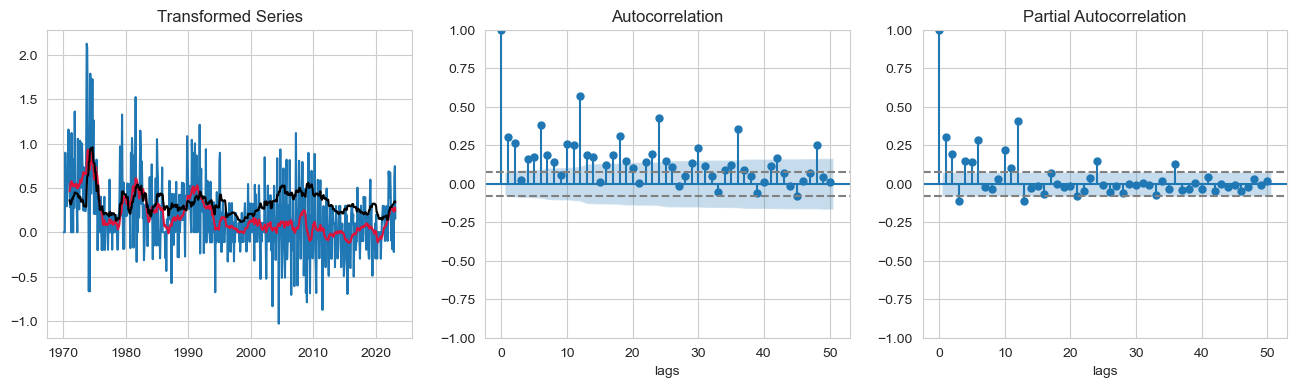
P-value = 0.064355, the series is likely non-stationary.
Switzerland_sample['Differenced'] = Switzerland_sample['Monthly Inflation Rate'].diff()
Switzerland_sample.dropna(inplace=True)
Switzerland_sample.head(20)
| YearMonth | HCPI | Monthly Inflation Rate | Differenced | |
|---|---|---|---|---|
| Date | ||||
| 1970-03-01 | 1970-03 | 33.4 | 0.0 | 0.0 |
| 1970-04-01 | 1970-04 | 33.4 | 0.0 | 0.0 |
| 1970-05-01 | 1970-05 | 33.7 | 0.898204 | 0.898204 |
| 1970-06-01 | 1970-06 | 33.9 | 0.593472 | -0.304732 |
| 1970-07-01 | 1970-07 | 34.0 | 0.294985 | -0.298487 |
| 1970-08-01 | 1970-08 | 34.1 | 0.294118 | -0.000868 |
| 1970-09-01 | 1970-09 | 34.3 | 0.58651 | 0.292393 |
| 1970-10-01 | 1970-10 | 34.5 | 0.58309 | -0.00342 |
| 1970-11-01 | 1970-11 | 34.9 | 1.15942 | 0.57633 |
| 1970-12-01 | 1970-12 | 35.1 | 0.573066 | -0.586354 |
| 1971-01-01 | 1971-01 | 35.3 | 0.569801 | -0.003265 |
| 1971-02-01 | 1971-02 | 35.4 | 0.283286 | -0.286514 |
| 1971-03-01 | 1971-03 | 35.7 | 0.847458 | 0.564172 |
| 1971-04-01 | 1971-04 | 35.7 | 0.0 | -0.847458 |
| 1971-05-01 | 1971-05 | 36.1 | 1.120448 | 1.120448 |
| 1971-06-01 | 1971-06 | 36.1 | 0.0 | -1.120448 |
| 1971-07-01 | 1971-07 | 36.3 | 0.554017 | 0.554017 |
| 1971-08-01 | 1971-08 | 36.3 | 0.0 | -0.554017 |
| 1971-09-01 | 1971-09 | 36.6 | 0.826446 | 0.826446 |
| 1971-10-01 | 1971-10 | 36.7 | 0.273224 | -0.553222 |
series_transformation(Switzerland_sample["Differenced"])
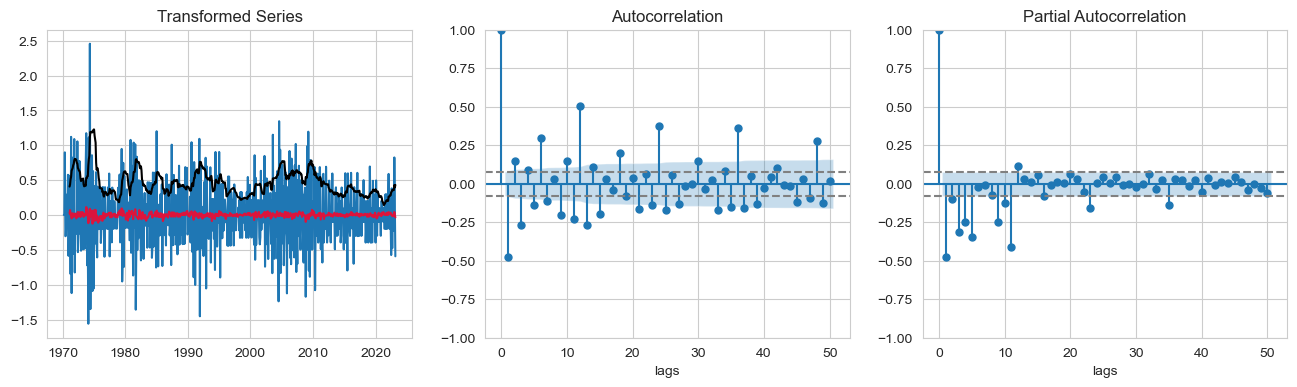
P-value = 0.000000, the series is likely stationary.
Observations:
- P-value: 0.064355 of ADF test shows slight non-stationary properties in the series.
- Taking first order differencing results in P-value of 0.00000, makes the series stationary.
- In auto-correlation plot, spikes at 0, 1,3,6,9,10,11, given the length of the time series we won’t consider all lags.
- In the partial autocorrection plot, we see significant spikes at 0,1,3,4,5,9 and 11, terms for moving average component of the time series, but we won’t consider all terms to avoid the risk of over-fitting.
- we can see how first order differencing changed the lags of autocorrection plot significantly and infunce the significant spikes in lags.
Switzerland_sample["Monthly Inflation Rate"] = Switzerland_sample["Monthly Inflation Rate"].astype(float)
Switzerland_sample.head(20)
| YearMonth | HCPI | Monthly Inflation Rate | Differenced | |
|---|---|---|---|---|
| Date | ||||
| 1970-03-01 | 1970-03 | 33.4 | 0.000000 | 0.0 |
| 1970-04-01 | 1970-04 | 33.4 | 0.000000 | 0.0 |
| 1970-05-01 | 1970-05 | 33.7 | 0.898204 | 0.898204 |
| 1970-06-01 | 1970-06 | 33.9 | 0.593472 | -0.304732 |
| 1970-07-01 | 1970-07 | 34.0 | 0.294985 | -0.298487 |
| 1970-08-01 | 1970-08 | 34.1 | 0.294118 | -0.000868 |
| 1970-09-01 | 1970-09 | 34.3 | 0.586510 | 0.292393 |
| 1970-10-01 | 1970-10 | 34.5 | 0.583090 | -0.00342 |
| 1970-11-01 | 1970-11 | 34.9 | 1.159420 | 0.57633 |
| 1970-12-01 | 1970-12 | 35.1 | 0.573066 | -0.586354 |
| 1971-01-01 | 1971-01 | 35.3 | 0.569801 | -0.003265 |
| 1971-02-01 | 1971-02 | 35.4 | 0.283286 | -0.286514 |
| 1971-03-01 | 1971-03 | 35.7 | 0.847458 | 0.564172 |
| 1971-04-01 | 1971-04 | 35.7 | 0.000000 | -0.847458 |
| 1971-05-01 | 1971-05 | 36.1 | 1.120448 | 1.120448 |
| 1971-06-01 | 1971-06 | 36.1 | 0.000000 | -1.120448 |
| 1971-07-01 | 1971-07 | 36.3 | 0.554017 | 0.554017 |
| 1971-08-01 | 1971-08 | 36.3 | 0.000000 | -0.554017 |
| 1971-09-01 | 1971-09 | 36.6 | 0.826446 | 0.826446 |
| 1971-10-01 | 1971-10 | 36.7 | 0.273224 | -0.553222 |
ARIMA Model:
Search ARIMA parameters:
series = Switzerland_sample["Monthly Inflation Rate"]
Full Data Parm Search:
train_size = int(len(series) * 0.9)
train, test = series[0:train_size], series[train_size:]
best_order = find_best_arima_params(train)
best_order
Best ARIMA(4, 1, 4) model - AIC: 382.45590772734045
(4, 1, 4)
best_order_metric = find_best_arima_params_metric(train)
best_order_metric
Best ARIMA(4, 0, 4) model - MSE: 0.11046128064195067
(4, 0, 4)
Train and predict using ARIMA model with the best ARIMA order extracted:
series = Switzerland_sample["Monthly Inflation Rate"]
train_size = int(len(series) * 0.8)
train, test = series[0:train_size], series[train_size:]
train = train[-100:]
best_order = (4, 1, 4)
model = ARIMA(train, order=best_order)
model_fit = model.fit()
forecast = model_fit.forecast(steps=len(test))
rmspe = np.sqrt(mean_squared_error(test, forecast))
test_length = len(test)
plt.figure(figsize=(25, 10))
plt.plot(train, label='Training Data')
plt.plot(test.index, forecast, color='red', label='Predicted')
plt.plot(test.index, test, color='green', linestyle='dashed', label='Actual')
plt.title("ARIMA"+str(best_order)+" Forecast vs Actuals", fontsize=20)
plt.legend(loc='best', prop={'size': 16})
plt.grid(True)
plt.annotate(f'RMSPE: {rmspe:.3f}', xy=(0.75, 0.95), xycoords='axes fraction',
fontsize=12, bbox=dict(boxstyle="round,pad=0.3", edgecolor="black", facecolor="aliceblue"))
plt.annotate(f'Test Length: {test_length} months', xy=(0.02, 0.95), xycoords='axes fraction',
fontsize=14, bbox=dict(boxstyle="round,pad=0.3", edgecolor="black", facecolor="aliceblue"))
years = pd.date_range(start=train.index.min(), end=test.index.max(), freq='2Y')
plt.xticks(years, years.strftime('%Y'), fontsize=14)
plt.yticks(fontsize=14)
plt.show()
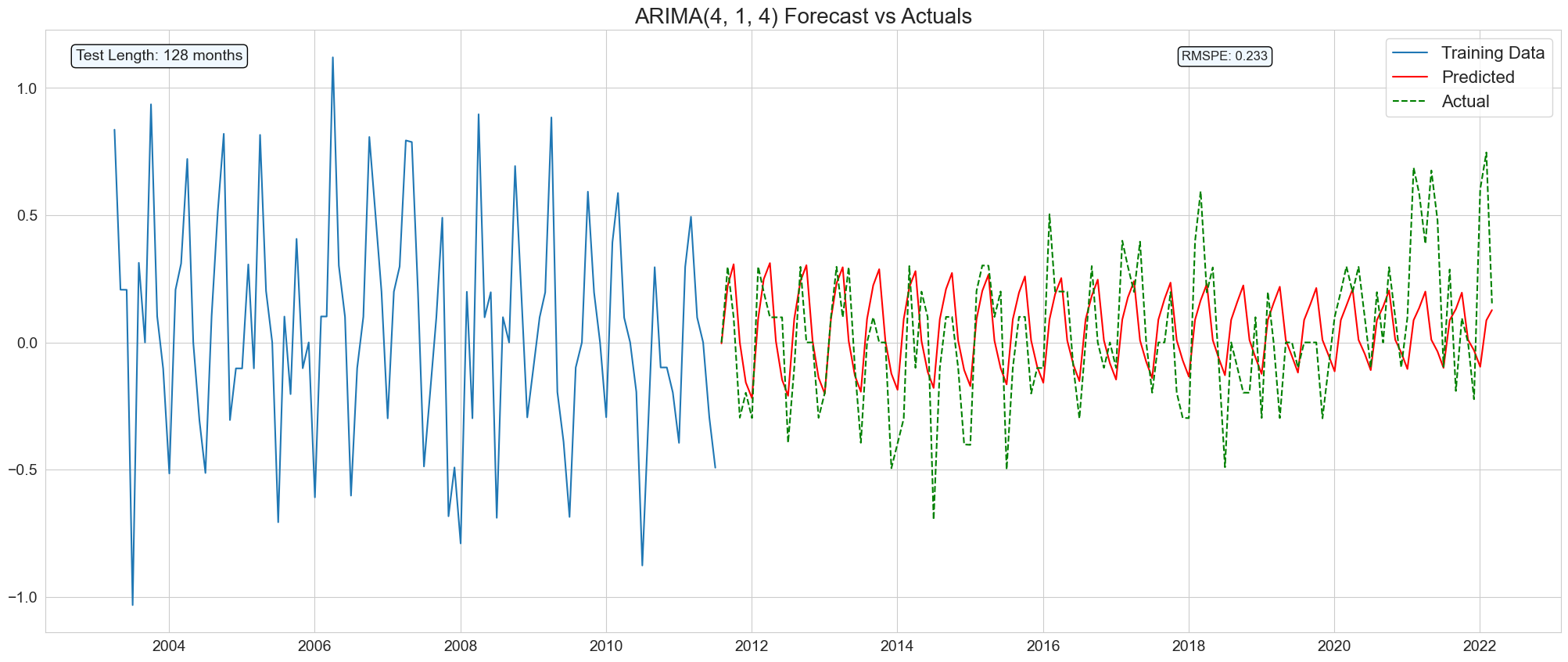
results_df = pd.DataFrame({
'Actual': test,
'Predicted': forecast
})
results_df
| Actual | Predicted | |
|---|---|---|
| 2012-08-01 | 0.000000 | -0.003746 |
| 2012-09-01 | 0.296736 | 0.221879 |
| 2012-10-01 | 0.098619 | 0.307202 |
| 2012-11-01 | -0.295567 | -0.000672 |
| 2012-12-01 | -0.197628 | -0.157315 |
| ... | ... | ... |
| 2022-11-01 | 0.000000 | 0.010762 |
| 2022-12-01 | -0.223070 | -0.031386 |
| 2023-01-01 | 0.601915 | -0.095671 |
| 2023-02-01 | 0.746467 | 0.086958 |
| 2023-03-01 | 0.153655 | 0.127167 |
128 rows × 2 columns
SARIMAX Model:
Search SARIMAX Parameters Space:
model =auto_arima(train,
start_p=1,
start_q=1,
max_p=8,
max_q=8,
start_P=0,
start_Q=0,
max_P=8,
max_Q=8,
m=12,
seasonal=True,
trace=True,
d=1,
D=1,
error_action='warn',
suppress_warnings=True,
random_state = 20,
n_fits=100)
print(model.summary())
Performing stepwise search to minimize aic
ARIMA(1,1,1)(0,1,0)[12] : AIC=80.006, Time=0.02 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=116.568, Time=0.01 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=76.938, Time=0.08 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=inf, Time=0.59 sec
ARIMA(1,1,0)(0,1,0)[12] : AIC=89.617, Time=0.03 sec
ARIMA(1,1,0)(2,1,0)[12] : AIC=64.576, Time=0.85 sec
ARIMA(1,1,0)(3,1,0)[12] : AIC=66.550, Time=0.41 sec
ARIMA(1,1,0)(2,1,1)[12] : AIC=66.486, Time=1.30 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=67.003, Time=0.13 sec
ARIMA(1,1,0)(3,1,1)[12] : AIC=inf, Time=1.84 sec
ARIMA(0,1,0)(2,1,0)[12] : AIC=91.023, Time=0.10 sec
ARIMA(2,1,0)(2,1,0)[12] : AIC=64.008, Time=0.40 sec
ARIMA(2,1,0)(1,1,0)[12] : AIC=73.340, Time=0.10 sec
ARIMA(2,1,0)(3,1,0)[12] : AIC=66.008, Time=0.67 sec
ARIMA(2,1,0)(2,1,1)[12] : AIC=66.007, Time=0.55 sec
ARIMA(2,1,0)(1,1,1)[12] : AIC=65.355, Time=0.23 sec
ARIMA(2,1,0)(3,1,1)[12] : AIC=inf, Time=2.03 sec
ARIMA(3,1,0)(2,1,0)[12] : AIC=59.600, Time=0.22 sec
ARIMA(3,1,0)(1,1,0)[12] : AIC=68.426, Time=0.12 sec
ARIMA(3,1,0)(3,1,0)[12] : AIC=61.456, Time=0.60 sec
ARIMA(3,1,0)(2,1,1)[12] : AIC=60.408, Time=1.20 sec
ARIMA(3,1,0)(1,1,1)[12] : AIC=59.438, Time=0.32 sec
ARIMA(3,1,0)(0,1,1)[12] : AIC=57.682, Time=0.13 sec
ARIMA(3,1,0)(0,1,0)[12] : AIC=81.509, Time=0.02 sec
ARIMA(3,1,0)(0,1,2)[12] : AIC=59.338, Time=0.45 sec
ARIMA(3,1,0)(1,1,2)[12] : AIC=inf, Time=1.05 sec
ARIMA(2,1,0)(0,1,1)[12] : AIC=63.492, Time=0.11 sec
ARIMA(4,1,0)(0,1,1)[12] : AIC=59.536, Time=0.13 sec
ARIMA(3,1,1)(0,1,1)[12] : AIC=inf, Time=1.04 sec
ARIMA(2,1,1)(0,1,1)[12] : AIC=inf, Time=0.91 sec
ARIMA(4,1,1)(0,1,1)[12] : AIC=inf, Time=0.66 sec
ARIMA(3,1,0)(0,1,1)[12] intercept : AIC=59.680, Time=0.27 sec
Best model: ARIMA(3,1,0)(0,1,1)[12]
Total fit time: 16.612 seconds
SARIMAX Results
============================================================================================
Dep. Variable: y No. Observations: 100
Model: SARIMAX(3, 1, 0)x(0, 1, [1], 12) Log Likelihood -23.841
Date: Mon, 13 Nov 2023 AIC 57.682
Time: 14:56:23 BIC 70.011
Sample: 04-01-2004 HQIC 62.646
- 07-01-2012
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.7077 0.142 -4.974 0.000 -0.987 -0.429
ar.L2 -0.3956 0.181 -2.191 0.028 -0.750 -0.042
ar.L3 -0.3042 0.135 -2.245 0.025 -0.570 -0.039
ma.S.L12 -0.7500 0.141 -5.333 0.000 -1.026 -0.474
sigma2 0.0898 0.014 6.219 0.000 0.061 0.118
===================================================================================
Ljung-Box (L1) (Q): 0.05 Jarque-Bera (JB): 12.57
Prob(Q): 0.83 Prob(JB): 0.00
Heteroskedasticity (H): 1.72 Skew: -0.76
Prob(H) (two-sided): 0.15 Kurtosis: 4.08
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
series = Switzerland_sample["Monthly Inflation Rate"]
train_size = int(len(series) * 0.8)
train, test = series[0:train_size], series[train_size:]
model = SARIMAX(train,
order=(3, 1, 0),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False,
)
model_fit = model.fit(disp=False)
forecast = model_fit.forecast(steps=len(test))
rmspe = np.sqrt(mean_squared_error(test, forecast))
plt.figure(figsize=(25, 10))
plt.plot(train, label='Training Data')
plt.plot(test.index, forecast, color='red', label='Predicted')
plt.plot(test.index, test, color='green', linestyle='dashed', label='Actual')
plt.title('SARIMA Model Forecast vs Actuals', fontsize=20)
plt.legend(loc='best', prop={'size': 14})
plt.grid(True)
plt.annotate(f'RMSPE: {rmspe:.3f}', xy=(0.75, 0.95), xycoords='axes fraction',
fontsize=12, bbox=dict(boxstyle="round,pad=0.3", edgecolor="black", facecolor="aliceblue"))
plt.yticks(fontsize=14)
plt.show()
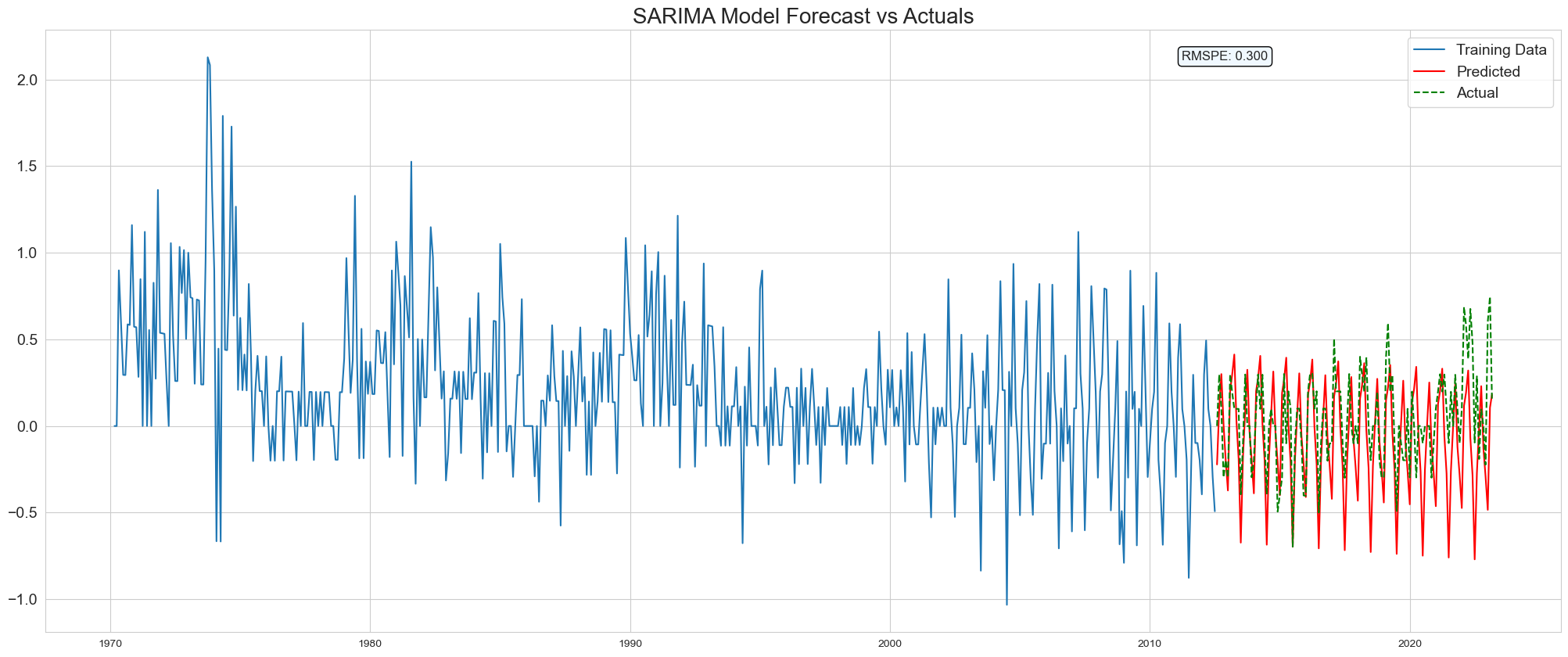
results_df = pd.DataFrame({
'Actual': test,
'Predicted': forecast
})
results_df
| Actual | Predicted | |
|---|---|---|
| 2012-08-01 | 0.000000 | -0.221922 |
| 2012-09-01 | 0.296736 | 0.105661 |
| 2012-10-01 | 0.098619 | 0.299608 |
| 2012-11-01 | -0.295567 | 0.008456 |
| 2012-12-01 | -0.197628 | -0.197302 |
| ... | ... | ... |
| 2022-11-01 | 0.000000 | -0.130700 |
| 2022-12-01 | -0.223070 | -0.291318 |
| 2023-01-01 | 0.601915 | -0.483904 |
| 2023-02-01 | 0.746467 | 0.105862 |
| 2023-03-01 | 0.153655 | 0.180592 |
128 rows × 2 columns
Further analysis of models:
Forecasting ARIMA:
def forecast_arima(series, order=(0, 0, 0)):
model = ARIMA(series, order=order)
model_fit = model.fit()
yhat = model_fit.predict(start=0, end=len(series)-1, typ='levels').rename('Predict')
plt.figure(figsize=(24, 10))
series.plot(legend=True, label='Actual', color='gray')
yhat.plot(legend=True, label='Predicted', color='yellow')
plt.title('Predict vs Actual Rates')
plt.legend()
plt.show()
forecast_arima(Switzerland_sample["Monthly Inflation Rate"], order=(4, 1, 4))
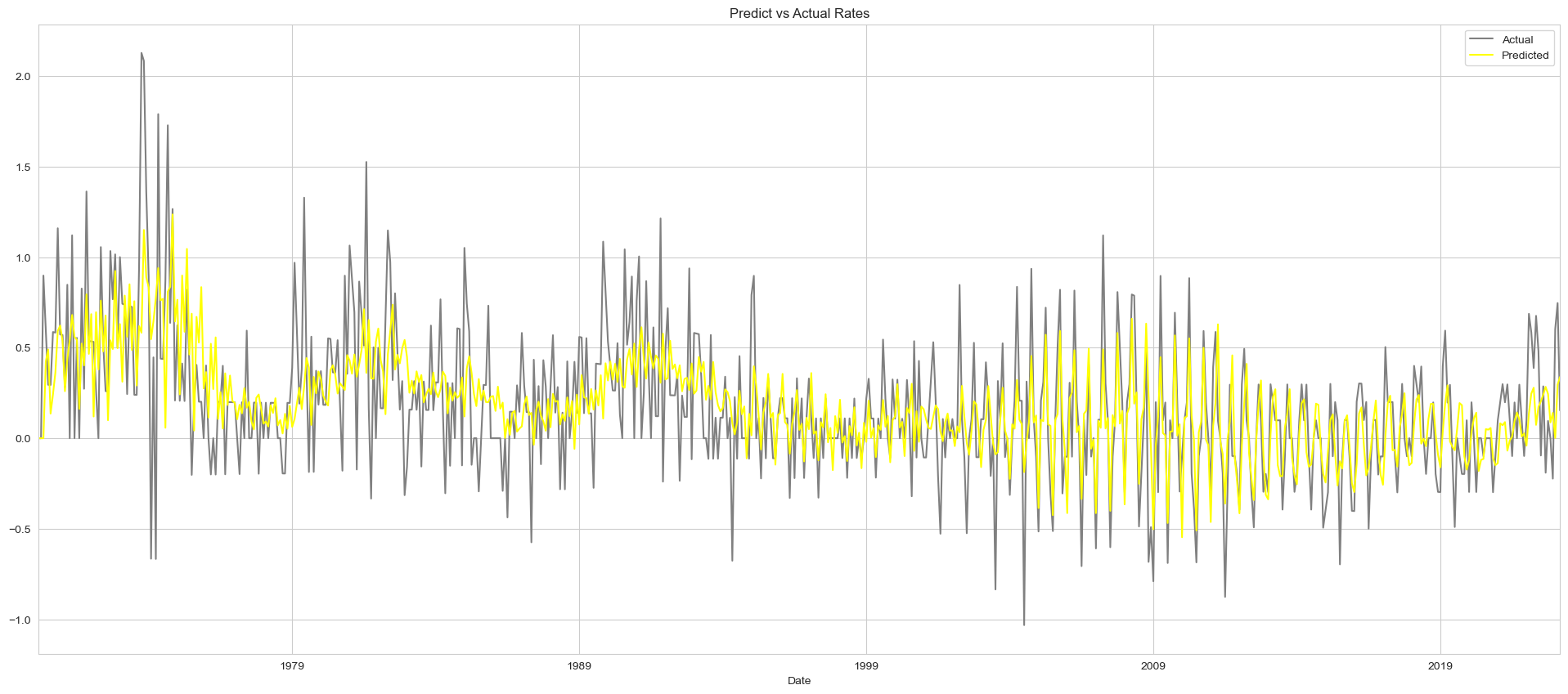
Forecasting with SARIMA:
def forecast_sarimax(series, order=(0, 0, 0), seasonal_order=(0, 0, 0, 0)):
sarimax_model = SARIMAX(series, order=order, seasonal_order=seasonal_order)
model_fitted = sarimax_model.fit(disp=False)
yhat = model_fitted.predict(start=0, end=len(series) - 1, typ='levels').rename('Predict')
plt.figure(figsize=(24, 10))
series.plot(legend=True, label='Actual', color='gray')
yhat.plot(legend=True, label='Predicted', color='green')
plt.title('Predict vs Actual Rates')
plt.legend()
plt.show()
forecast_sarimax(Switzerland_sample["Monthly Inflation Rate"],
order=(1,1,3),
seasonal_order=(1, 1, 1, 6))
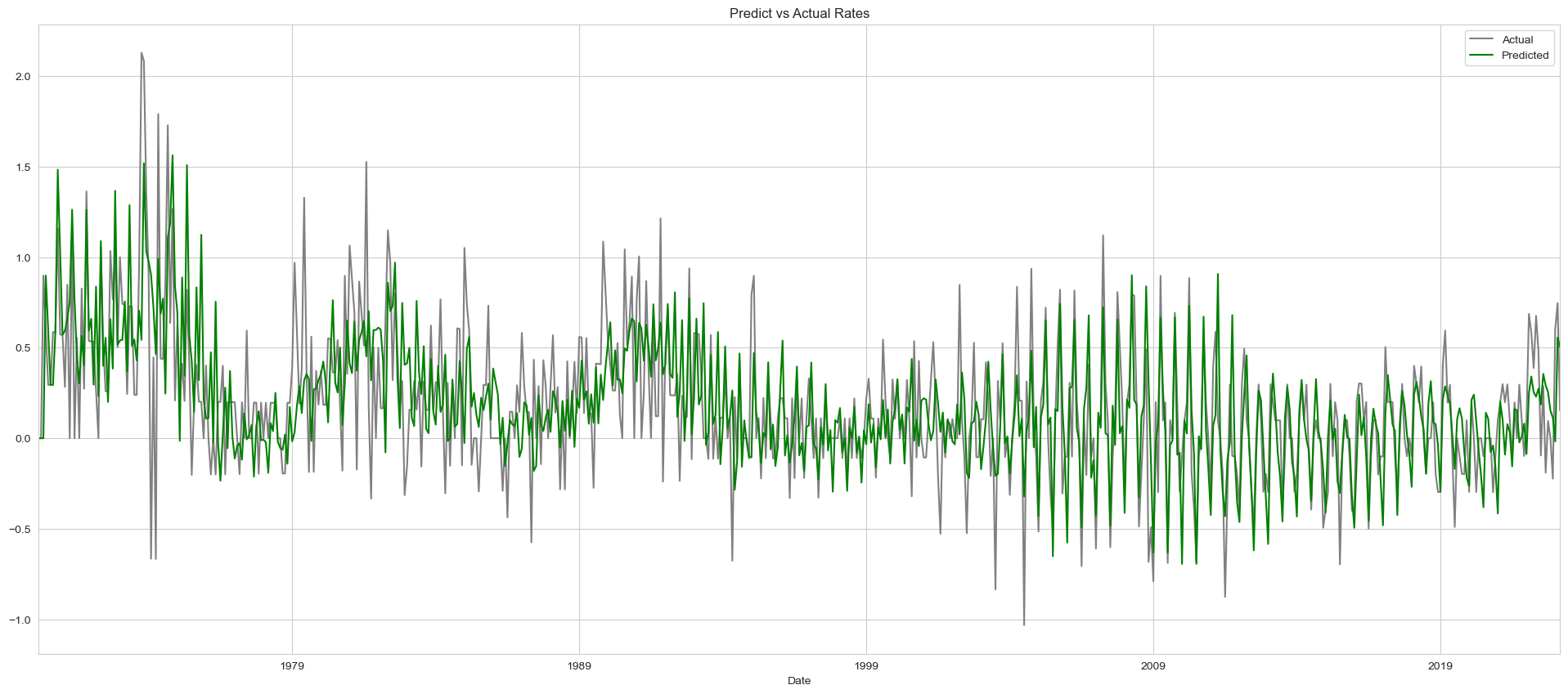
Generate Forecasting for the next 5 Years:
data = pd.read_csv("Monthly Inflation Rate")
data['Date'] = pd.to_datetime(data['Date'])
data.set_index('Date', inplace=True)
model =auto_arima(data["Monthly Inflation Rate"],
start_p=1,
start_q=1,
max_p=8,
max_q=8,
start_P=0,
start_Q=0,
max_P=8,
max_Q=8,
m=12,
seasonal=True,
trace=True,
d=1,
D=1,
error_action='warn',
suppress_warnings=True,
random_state = 222,
n_fits=200)
print(model.summary())
Performing stepwise search to minimize aic
ARIMA(1,1,1)(0,1,0)[12] : AIC=inf, Time=0.27 sec
ARIMA(0,1,0)(0,1,0)[12] : AIC=818.935, Time=0.04 sec
ARIMA(1,1,0)(1,1,0)[12] : AIC=561.232, Time=0.21 sec
ARIMA(0,1,1)(0,1,1)[12] : AIC=347.859, Time=0.39 sec
ARIMA(0,1,1)(0,1,0)[12] : AIC=inf, Time=0.23 sec
ARIMA(0,1,1)(1,1,1)[12] : AIC=338.815, Time=0.69 sec
ARIMA(0,1,1)(1,1,0)[12] : AIC=427.919, Time=0.21 sec
ARIMA(0,1,1)(2,1,1)[12] : AIC=339.446, Time=2.00 sec
ARIMA(0,1,1)(1,1,2)[12] : AIC=inf, Time=2.77 sec
ARIMA(0,1,1)(0,1,2)[12] : AIC=340.214, Time=1.30 sec
ARIMA(0,1,1)(2,1,0)[12] : AIC=379.938, Time=0.69 sec
ARIMA(0,1,1)(2,1,2)[12] : AIC=342.791, Time=2.11 sec
ARIMA(0,1,0)(1,1,1)[12] : AIC=627.173, Time=0.40 sec
ARIMA(1,1,1)(1,1,1)[12] : AIC=330.780, Time=1.03 sec
ARIMA(1,1,1)(0,1,1)[12] : AIC=342.710, Time=0.53 sec
ARIMA(1,1,1)(1,1,0)[12] : AIC=422.793, Time=0.40 sec
ARIMA(1,1,1)(2,1,1)[12] : AIC=331.941, Time=4.00 sec
ARIMA(1,1,1)(1,1,2)[12] : AIC=inf, Time=3.96 sec
ARIMA(1,1,1)(0,1,2)[12] : AIC=332.372, Time=1.78 sec
ARIMA(1,1,1)(2,1,0)[12] : AIC=375.191, Time=0.96 sec
ARIMA(1,1,1)(2,1,2)[12] : AIC=334.780, Time=3.62 sec
ARIMA(1,1,0)(1,1,1)[12] : AIC=474.992, Time=0.38 sec
ARIMA(2,1,1)(1,1,1)[12] : AIC=inf, Time=1.84 sec
ARIMA(1,1,2)(1,1,1)[12] : AIC=337.948, Time=2.22 sec
ARIMA(0,1,2)(1,1,1)[12] : AIC=332.736, Time=0.89 sec
ARIMA(2,1,0)(1,1,1)[12] : AIC=459.315, Time=0.58 sec
ARIMA(2,1,2)(1,1,1)[12] : AIC=315.711, Time=2.06 sec
ARIMA(2,1,2)(0,1,1)[12] : AIC=324.917, Time=1.24 sec
ARIMA(2,1,2)(1,1,0)[12] : AIC=inf, Time=2.04 sec
ARIMA(2,1,2)(2,1,1)[12] : AIC=316.615, Time=5.25 sec
ARIMA(2,1,2)(1,1,2)[12] : AIC=inf, Time=7.54 sec
ARIMA(2,1,2)(0,1,0)[12] : AIC=inf, Time=0.58 sec
ARIMA(2,1,2)(0,1,2)[12] : AIC=316.987, Time=6.32 sec
ARIMA(2,1,2)(2,1,0)[12] : AIC=362.643, Time=2.27 sec
ARIMA(2,1,2)(2,1,2)[12] : AIC=319.697, Time=6.48 sec
ARIMA(3,1,2)(1,1,1)[12] : AIC=316.117, Time=2.41 sec
ARIMA(2,1,3)(1,1,1)[12] : AIC=316.542, Time=2.81 sec
ARIMA(1,1,3)(1,1,1)[12] : AIC=314.586, Time=1.84 sec
ARIMA(1,1,3)(0,1,1)[12] : AIC=324.446, Time=0.95 sec
ARIMA(1,1,3)(1,1,0)[12] : AIC=411.107, Time=0.76 sec
ARIMA(1,1,3)(2,1,1)[12] : AIC=315.638, Time=5.87 sec
ARIMA(1,1,3)(1,1,2)[12] : AIC=inf, Time=8.27 sec
ARIMA(1,1,3)(0,1,0)[12] : AIC=inf, Time=0.52 sec
ARIMA(1,1,3)(0,1,2)[12] : AIC=315.888, Time=3.15 sec
ARIMA(1,1,3)(2,1,0)[12] : AIC=361.869, Time=1.18 sec
ARIMA(1,1,3)(2,1,2)[12] : AIC=318.582, Time=5.43 sec
ARIMA(0,1,3)(1,1,1)[12] : AIC=324.341, Time=2.38 sec
ARIMA(1,1,4)(1,1,1)[12] : AIC=316.536, Time=2.85 sec
ARIMA(0,1,4)(1,1,1)[12] : AIC=323.005, Time=3.31 sec
ARIMA(2,1,4)(1,1,1)[12] : AIC=318.585, Time=2.21 sec
ARIMA(1,1,3)(1,1,1)[12] intercept : AIC=316.478, Time=2.85 sec
Best model: ARIMA(1,1,3)(1,1,1)[12]
Total fit time: 114.130 seconds
SARIMAX Results
============================================================================================
Dep. Variable: y No. Observations: 637
Model: SARIMAX(1, 1, 3)x(1, 1, [1], 12) Log Likelihood -150.293
Date: Mon, 13 Nov 2023 AIC 314.586
Time: 14:58:21 BIC 345.639
Sample: 03-01-1970 HQIC 326.653
- 03-01-2023
Covariance Type: opg
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 -0.8296 0.070 -11.838 0.000 -0.967 -0.692
ma.L1 0.0611 0.071 0.856 0.392 -0.079 0.201
ma.L2 -0.6958 0.067 -10.333 0.000 -0.828 -0.564
ma.L3 -0.2184 0.037 -5.875 0.000 -0.291 -0.146
ar.S.L12 0.2222 0.045 4.924 0.000 0.134 0.311
ma.S.L12 -0.8442 0.030 -27.891 0.000 -0.904 -0.785
sigma2 0.0928 0.004 24.549 0.000 0.085 0.100
===================================================================================
Ljung-Box (L1) (Q): 0.03 Jarque-Bera (JB): 112.10
Prob(Q): 0.86 Prob(JB): 0.00
Heteroskedasticity (H): 0.36 Skew: -0.08
Prob(H) (two-sided): 0.00 Kurtosis: 5.07
===================================================================================
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
model = sm.tsa.statespace.SARIMAX(data["Monthly Inflation Rate"],
order=(1,1,3),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=True,
enforce_invertibility=True)
fit_model = model.fit(disp=False)
forecast = fit_model.get_forecast(steps=60)
predicted_mean = forecast.predicted_mean
conf_int = forecast.conf_int()
predicted_mean, conf_int.head()
forecast_index = pd.date_range(data.index[-1], periods=60, freq='MS')
yearly_predicted_mean = predicted_mean.resample('Y').sum()
yearly_predicted_mean.index = yearly_predicted_mean.index.year
yearly_predicted_mean.index = pd.to_datetime(yearly_predicted_mean.index, format='%Y')
yearly_conf_int_lower = conf_int['lower Monthly Inflation Rate'].resample('Y').sum()
yearly_conf_int_upper = conf_int['upper Monthly Inflation Rate'].resample('Y').sum()
yearly_data = data.resample('Y').sum()
yearly_data.index = yearly_data.index.year
yearly_data.index = pd.to_datetime(yearly_data.index, format='%Y')
plt.figure(figsize=(20, 7))
plt.plot(yearly_data.index, yearly_data['Monthly Inflation Rate'], label='Historical Data', color='blue')
plt.plot(yearly_predicted_mean.index, yearly_predicted_mean, label='Yearly Forecast', color='red', linestyle='--')
ax = plt.gca()
ax.xaxis.set_major_locator(mdates.YearLocator(2))
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y'))
ymin, ymax = plt.ylim()
plt.yticks(np.arange(ymin, ymax, (ymax-ymin)/20))
ax.tick_params(axis='x', labelsize=12)
ax.tick_params(axis='y', labelsize=12)
for date, value in zip(yearly_data.index, yearly_data['Monthly Inflation Rate']):
ax.annotate(f'{value:.2f}', (date, value), textcoords="offset points", xytext=(0,5), ha='center', fontsize=10)
for date, value in zip(yearly_predicted_mean.index, yearly_predicted_mean):
ax.annotate(f'{value:.2f}', (date, value), textcoords="offset points", xytext=(0,5), ha='center', fontsize=10, color='red')
plt.title('Yearly Inflation Rate and Forecast for Switzerland (2024-2028) - SARIMAX Model', fontsize=18)
plt.xlabel('Date', fontsize=16)
plt.ylabel('Yearly Inflation Rate (%)', fontsize=16)
plt.legend(fontsize='x-large')
plt.grid(True)
plt.tight_layout()
plt.show()
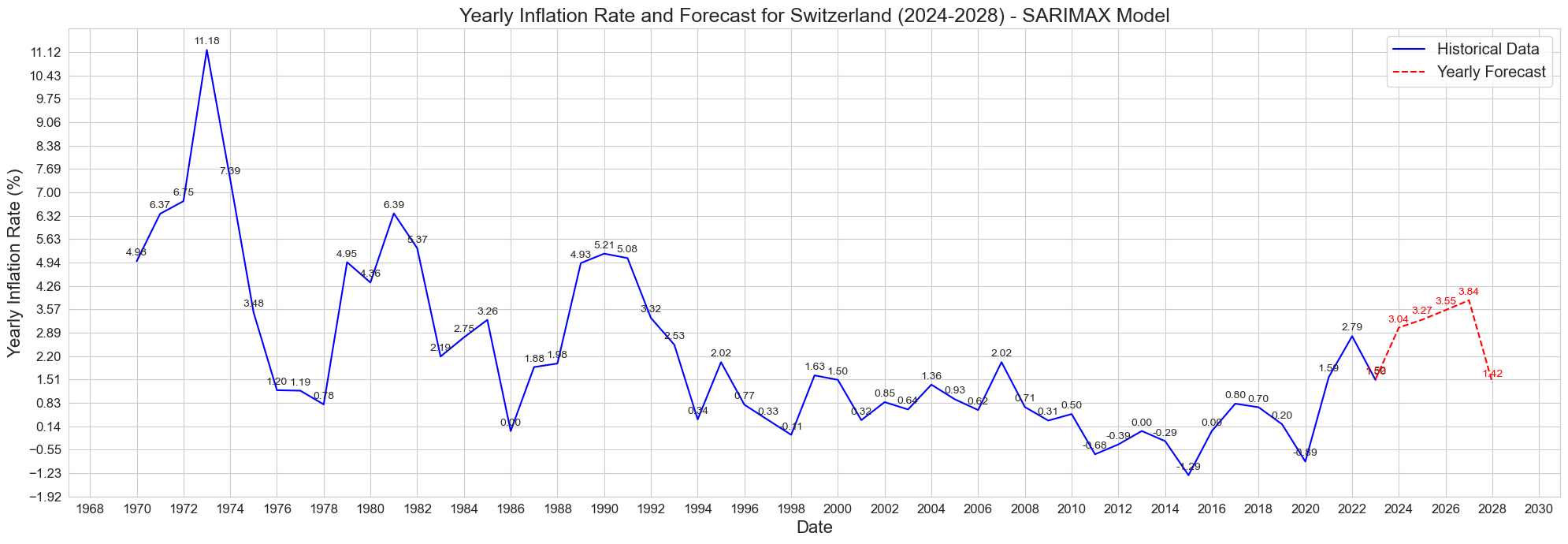
How far such model can predict inflation rate accurately?
Given the limitation of the uni-variate data we have previously used in forecasting inflation and experimenting with different models, one question came to mind is how far we can forecast inflation from a previous pattern of the data. Given the monetary series stochastic nature and the many random factors that influences the change in inflation over the years, it is always better to state with humility the limitation of the data the model.
data = pd.read_csv("Monthly Inflation Rate")
data['Date'] = pd.to_datetime(data['Date'])
data.set_index('Date', inplace=True)
Split and prepare data:
series = data["Monthly Inflation Rate"]
train_end_index = int(0.8 * len(series))
train_data = series.iloc[:train_end_index]
start_test = train_end_index
test_data = []
test_labels = []
for i in range(1, 11):
end_test = start_test + 6 * i
test_split = series.iloc[train_end_index:end_test]
test_data.append(test_split)
test_labels.append(f"{i * 6} months")
test_data = test_data[:5] + [test_data[-3], test_data[-2], test_data[-1]]
test_labels = test_labels[:5] + [test_labels[-3], test_labels[-2], test_labels[-1]]
predictions = []
rmses = []
results = []
for i, test in enumerate(test_data):
model_ = ARIMA(train_data,
order=(4, 1, 4),
)
fit_model = model_.fit()
forecast = fit_model.forecast(steps=len(test))
predictions.append(forecast)
rmse = np.sqrt(mean_squared_error(test, forecast))
rmses.append(rmse)
print(f'RMSE for {test_labels[i]} test set: {rmse:.2f}')
fig, ax = plt.subplots(1, 2, figsize=(20,7))
font_size_axis = 14
ax[0].tick_params(axis='both', labelsize=font_size_axis)
ax[1].tick_params(axis='both', labelsize=font_size_axis)
ax[0].plot(series.index[:train_end_index + len(forecast)], series.values[:train_end_index + len(forecast)], label='Original Series', color='blue')
fitted_indices = series.index[train_end_index - len(fit_model.fittedvalues):train_end_index]
ax[0].plot(fitted_indices, fit_model.fittedvalues, color='red', label='Fitted Values')
forecast_index = range(train_end_index, train_end_index + len(forecast))
ax[0].plot(series.index[forecast_index], forecast, label=f'Forecast {test_labels[i]}', color='green')
font_size_legend = 12
font_size_title = 16
ax[0].legend(fontsize=font_size_legend)
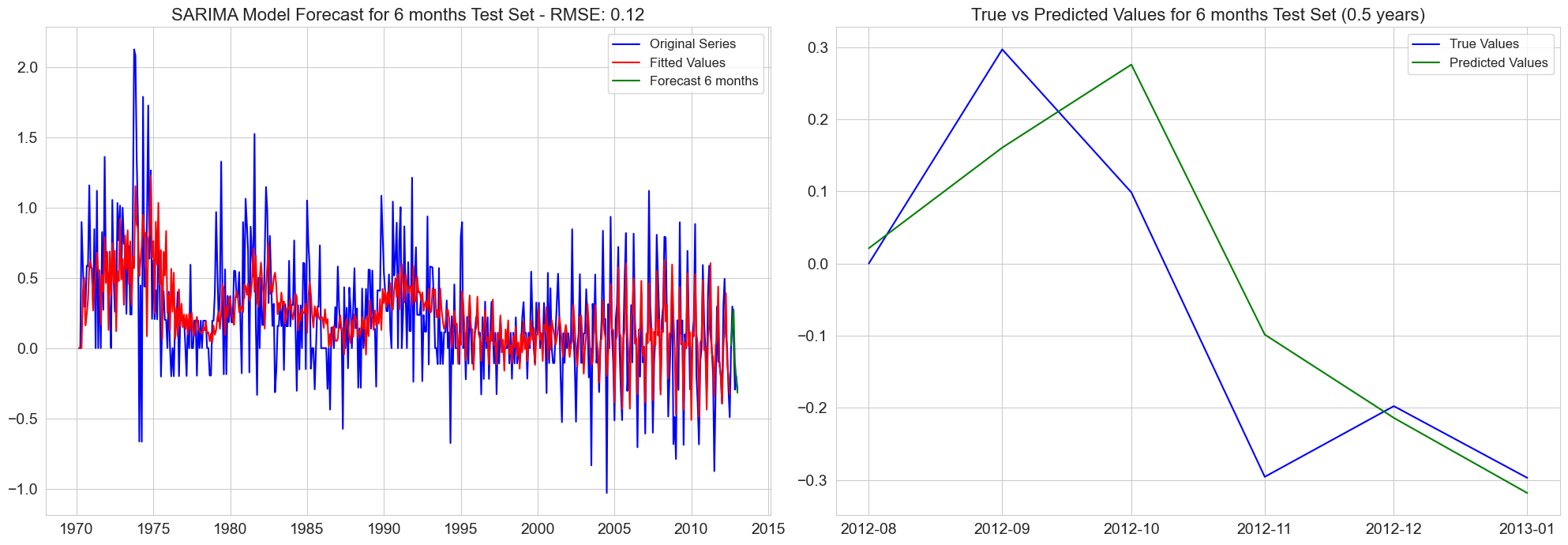
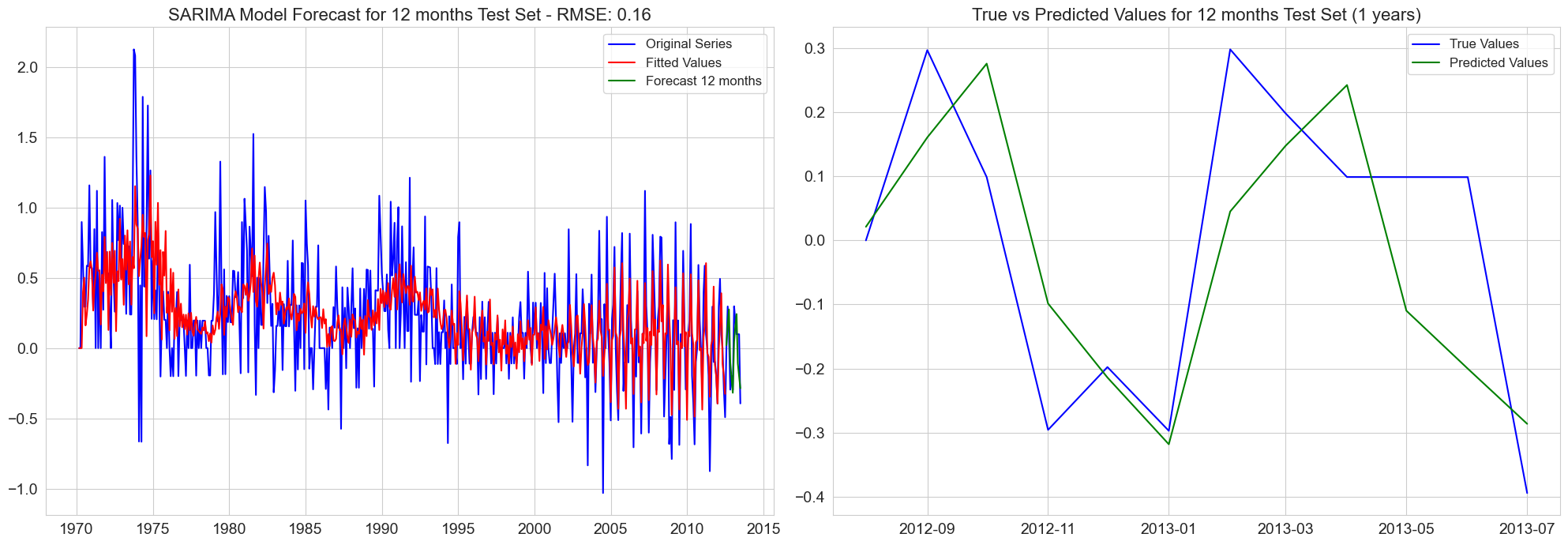
ax[0].set_title(f'SARIMA Model Forecast for {test_labels[i]} Test Set - RMSE: {rmse:.2f}', fontsize=font_size_title)
ax[1].plot(series.index[forecast_index], test, label='True Values', color='blue')
ax[1].plot(series.index[forecast_index], forecast, label='Predicted Values', color='green')
test_length_years = format_year(len(test) / 12.0)
ax[1].set_title(f'True vs Predicted Values for {test_labels[i]} Test Set ({test_length_years} years)', fontsize=font_size_title)
ax[1].legend(fontsize=font_size_legend)
plt.tight_layout()
plt.show()
df = pd.DataFrame({
'Date': series.index[forecast_index],
'True Values': test.values,
'Predicted Values': forecast,
'Forecasting in Months':test_labels[i],
'Test Set Label':i,
'Years': test_length_years
})
results.append(df)
RMSE for 6 months test set: 0.12
RMSE for 12 months test set: 0.16
RMSE for 18 months test set: 0.16
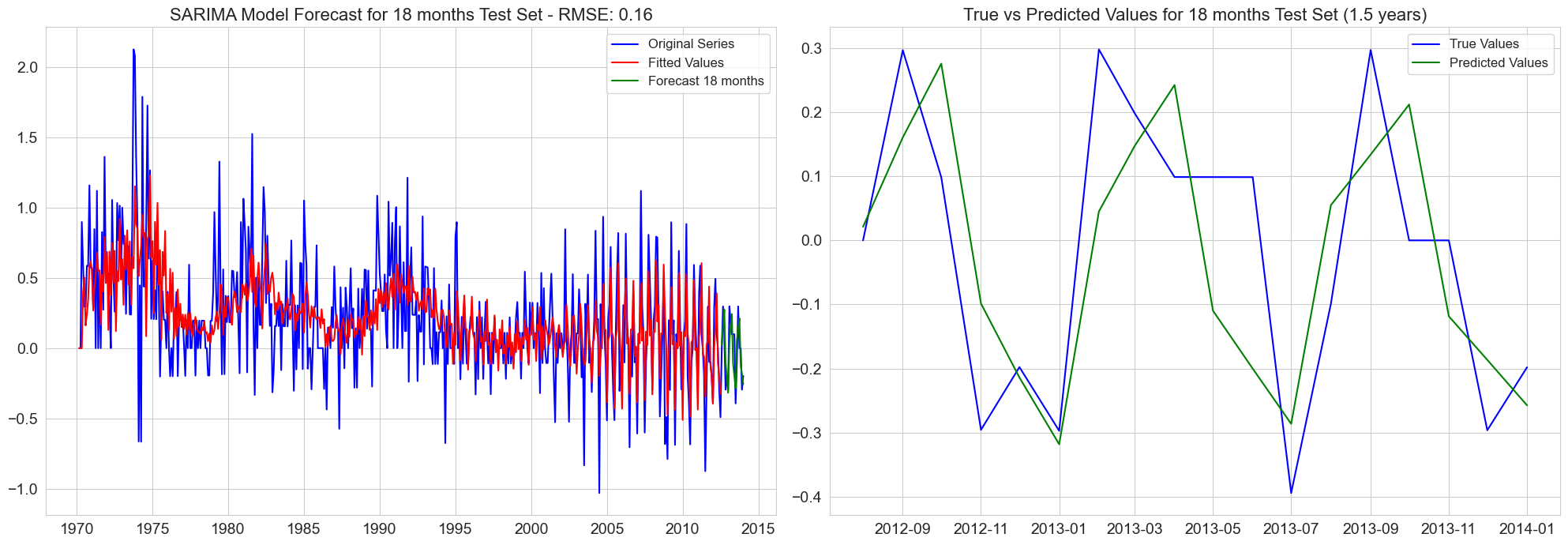
RMSE for 24 months test set: 0.17
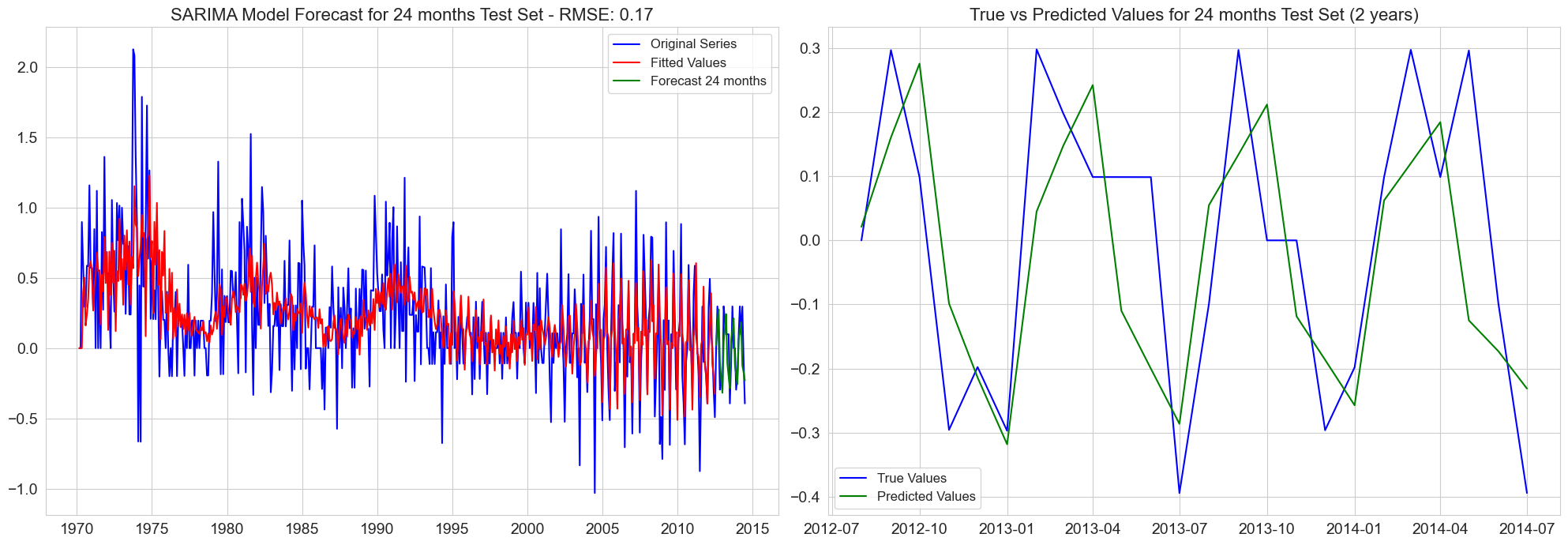
RMSE for 30 months test set: 0.17
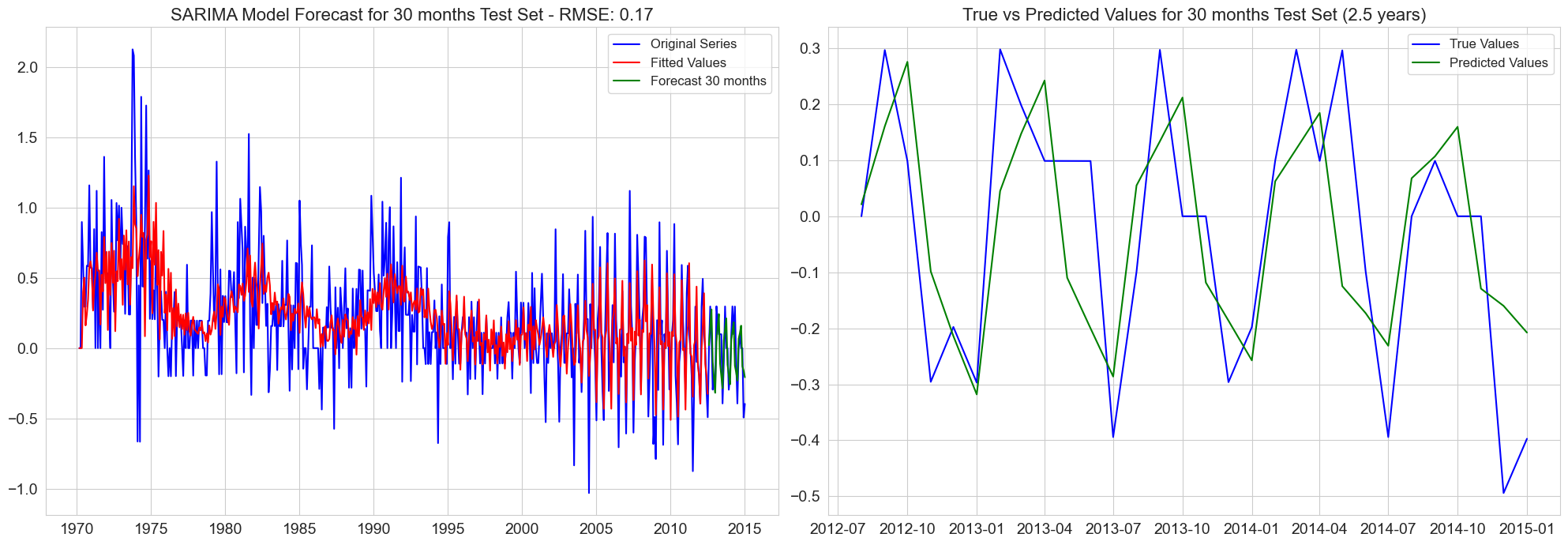
RMSE for 48 months test set: 0.21
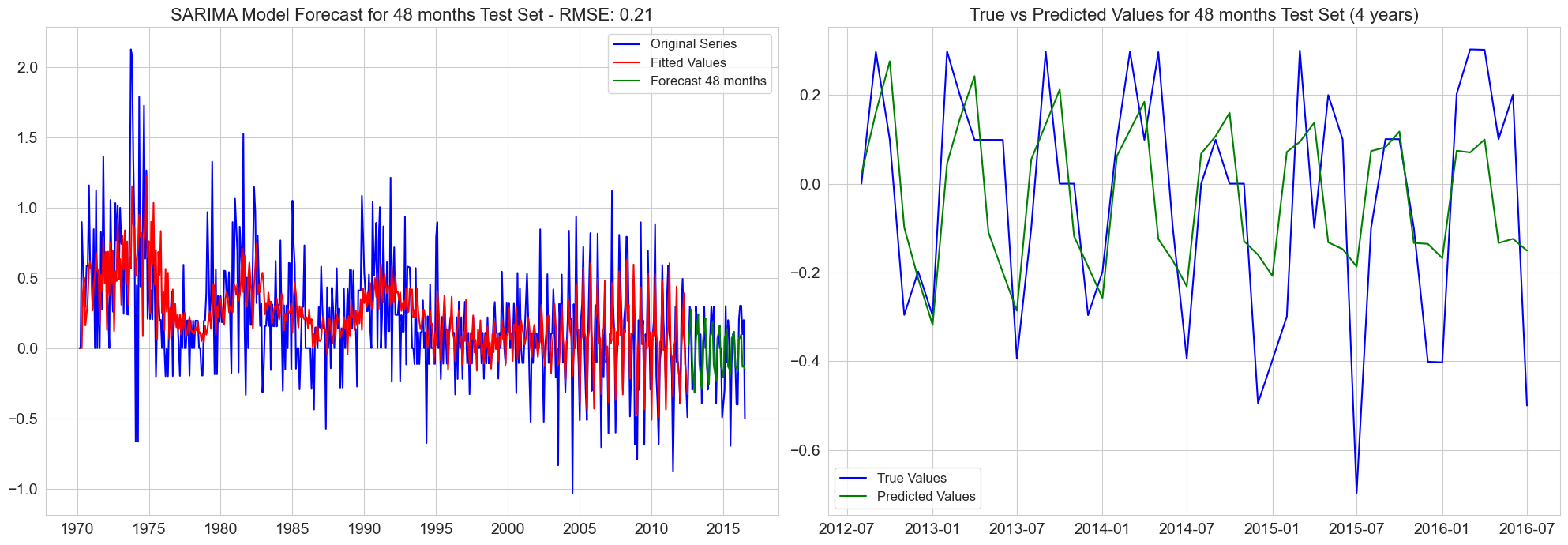
RMSE for 54 months test set: 0.20
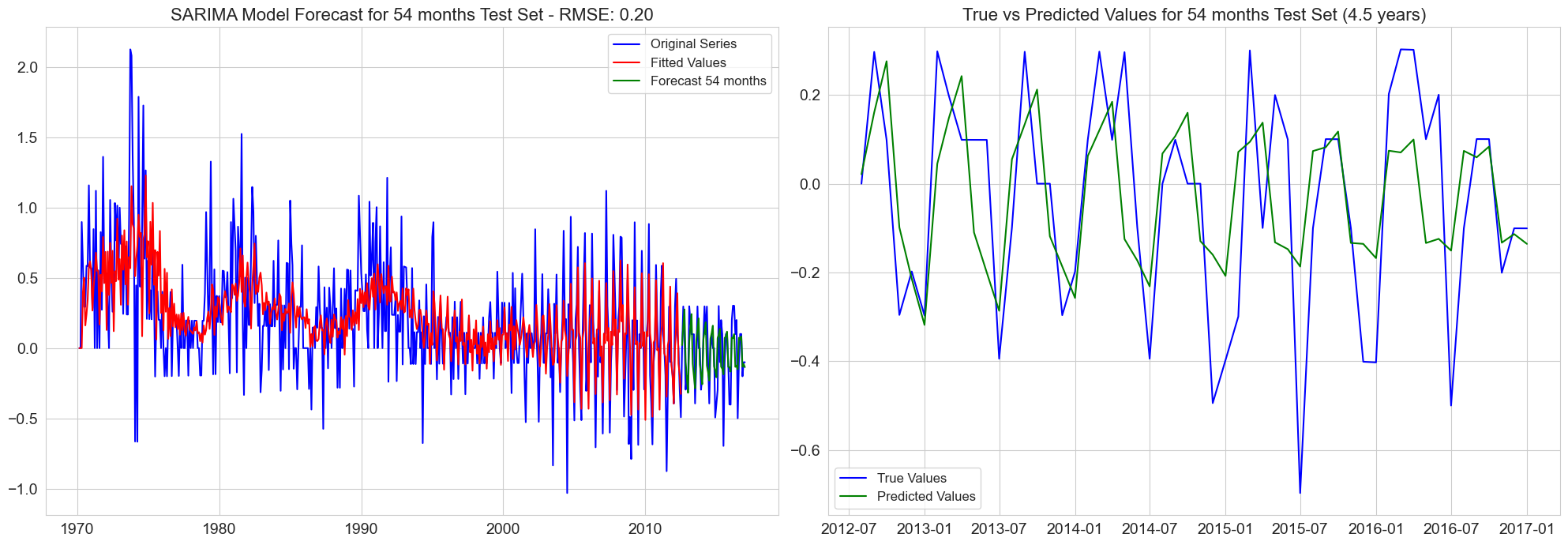
RMSE for 60 months test set: 0.20
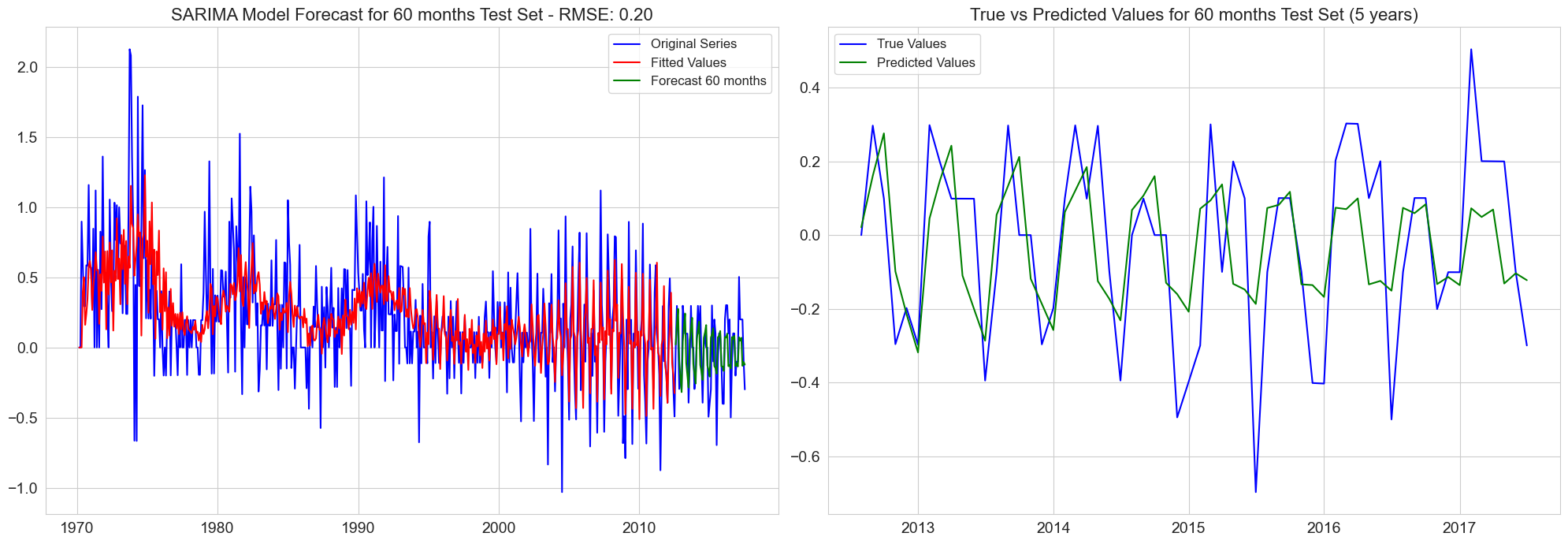
predictions = []
rmses = []
results = []
for i, test in enumerate(test_data):
model_ = sm.tsa.statespace.SARIMAX(train_data,
order=(1,1,3),
seasonal_order=(2, 0, 1, 12),
enforce_stationarity=True,
enforce_invertibility=True)
fit_model = model_.fit(optimized=True, use_brute=True,disp=False)
forecast = fit_model.forecast(steps=len(test))
predictions.append(forecast)
rmse = np.sqrt(mean_squared_error(test, forecast))
rmses.append(rmse)
print(f'RMSE for {test_labels[i]} test set: {rmse:.2f}')
fig, ax = plt.subplots(1, 2, figsize=(20,7))
font_size_axis = 14
ax[0].tick_params(axis='both', labelsize=font_size_axis)
ax[1].tick_params(axis='both', labelsize=font_size_axis)
ax[0].plot(series.index[:train_end_index + len(forecast)], series.values[:train_end_index + len(forecast)], label='Original Series', color='blue')
fitted_indices = series.index[train_end_index - len(fit_model.fittedvalues):train_end_index]
ax[0].plot(fitted_indices, fit_model.fittedvalues, color='red', label='Fitted Values')
forecast_index = range(train_end_index, train_end_index + len(forecast))
ax[0].plot(series.index[forecast_index], forecast, label=f'Forecast {test_labels[i]}', color='yellow')
font_size_legend = 12
font_size_title = 16
ax[0].legend(fontsize=font_size_legend)
ax[0].set_title(f'SARIMA Model Forecast for {test_labels[i]} Test Set - RMSE: {rmse:.2f}', fontsize=font_size_title)
ax[1].plot(series.index[forecast_index], test, label='True Values', color='blue')
ax[1].plot(series.index[forecast_index], forecast, label='Predicted Values', color='yellow')
test_length_years = format_year(len(test) / 12.0)
ax[1].set_title(f'True vs Predicted Values for {test_labels[i]} Test Set ({test_length_years} years)', fontsize=font_size_title)
ax[1].legend(fontsize=font_size_legend)
plt.tight_layout()
plt.show()
df = pd.DataFrame({
'Date': series.index[forecast_index],
'True Values': test.values,
'Predicted Values': forecast,
'Forecasting in Months':test_labels[i],
'Test Set Label':i,
'Years': test_length_years
})
results.append(df)
RMSE for 6 months test set: 0.15
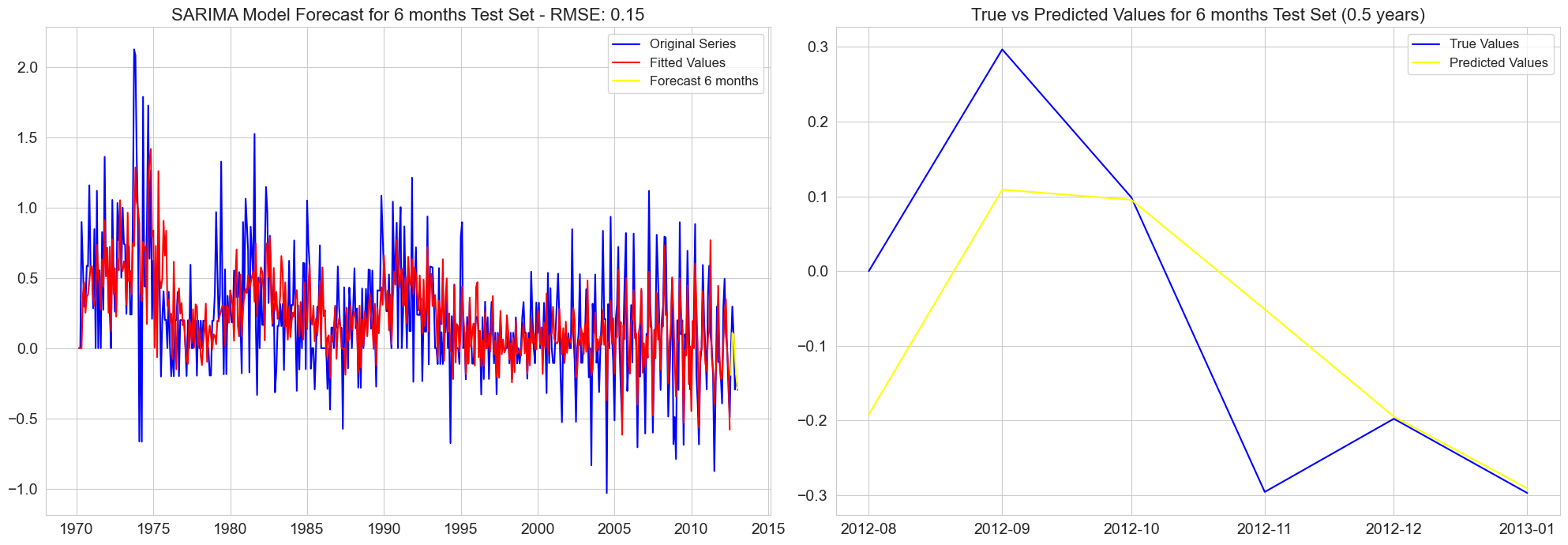
RMSE for 12 months test set: 0.15
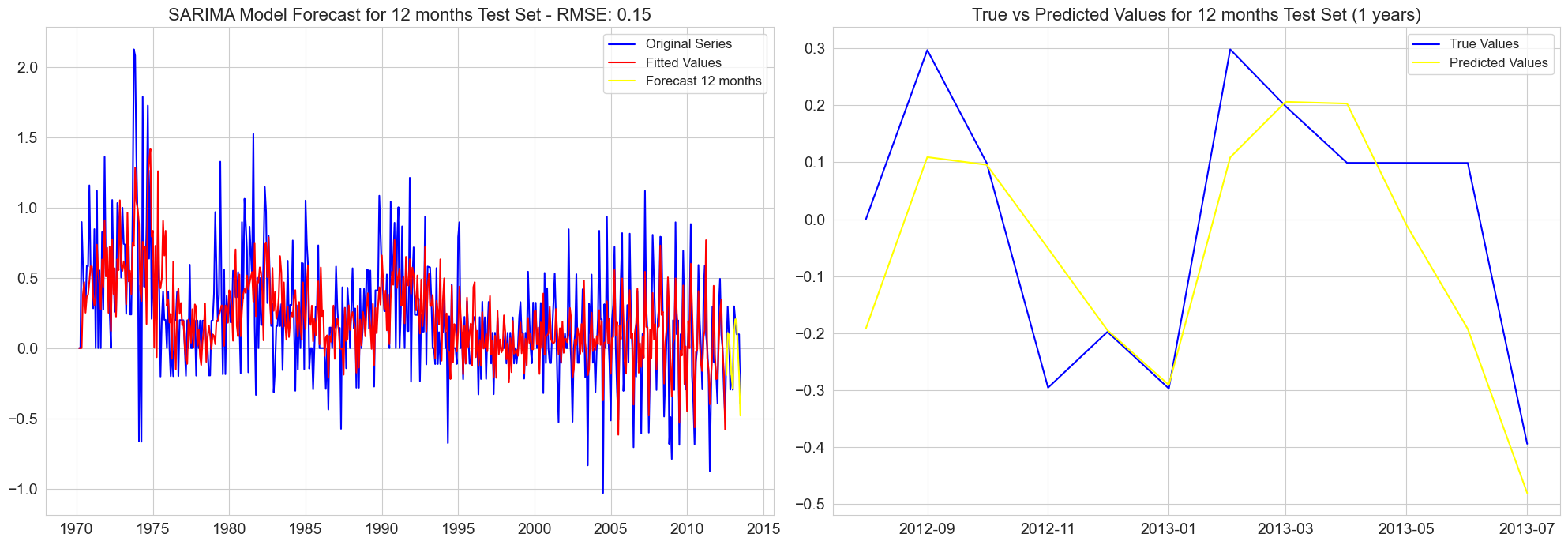
RMSE for 18 months test set: 0.15
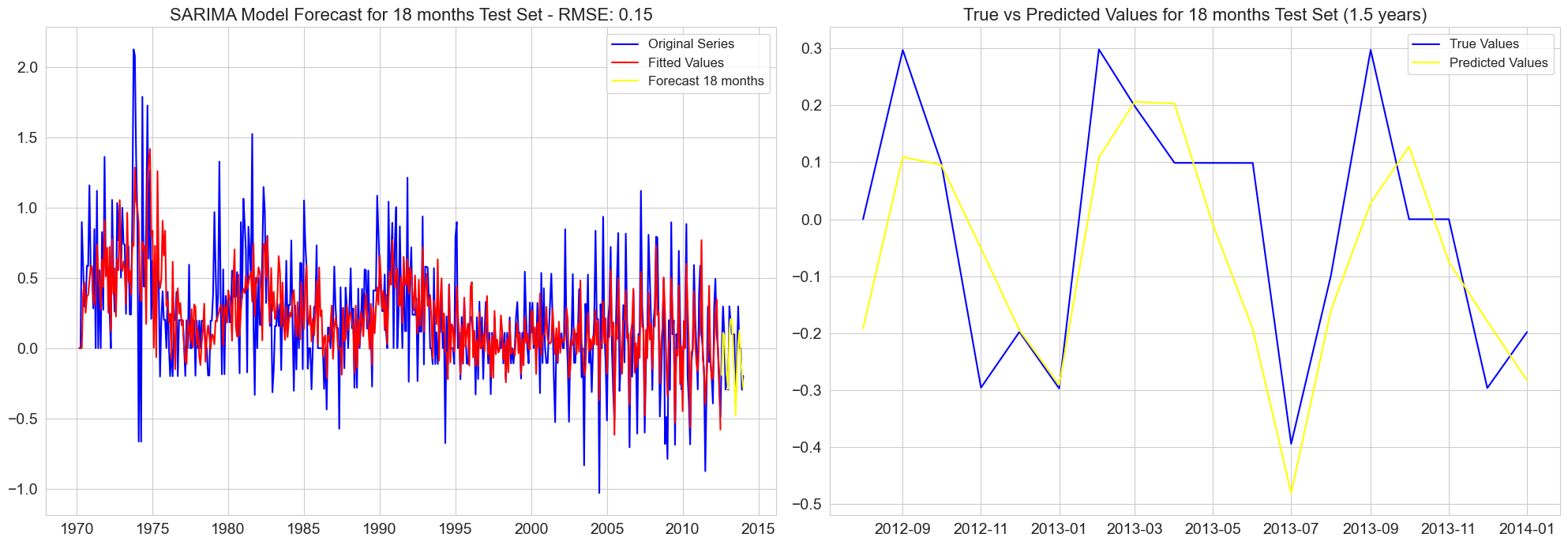
RMSE for 24 months test set: 0.15
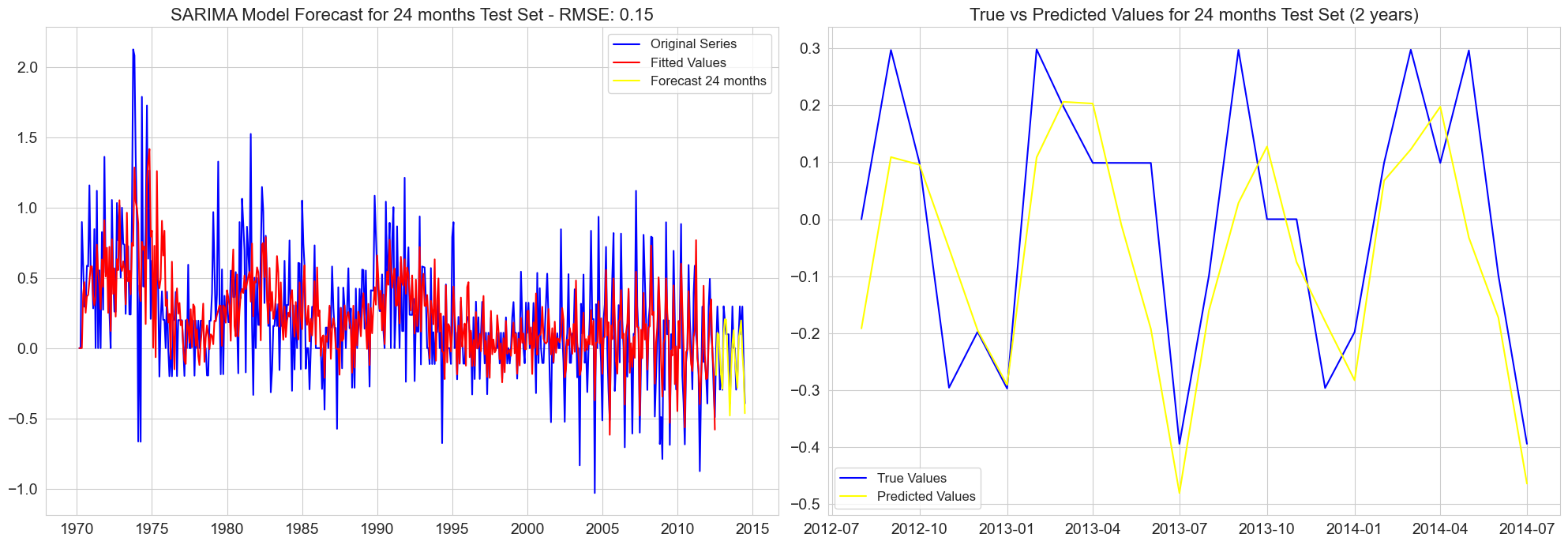
RMSE for 30 months test set: 0.16
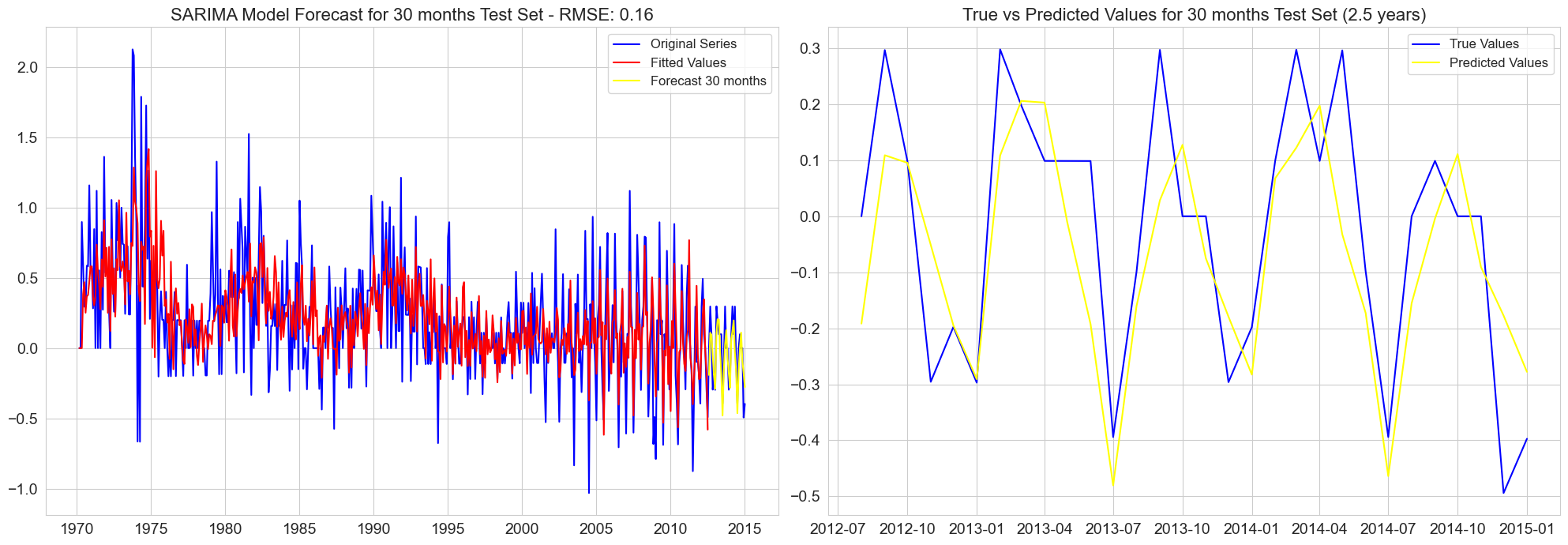
RMSE for 48 months test set: 0.18
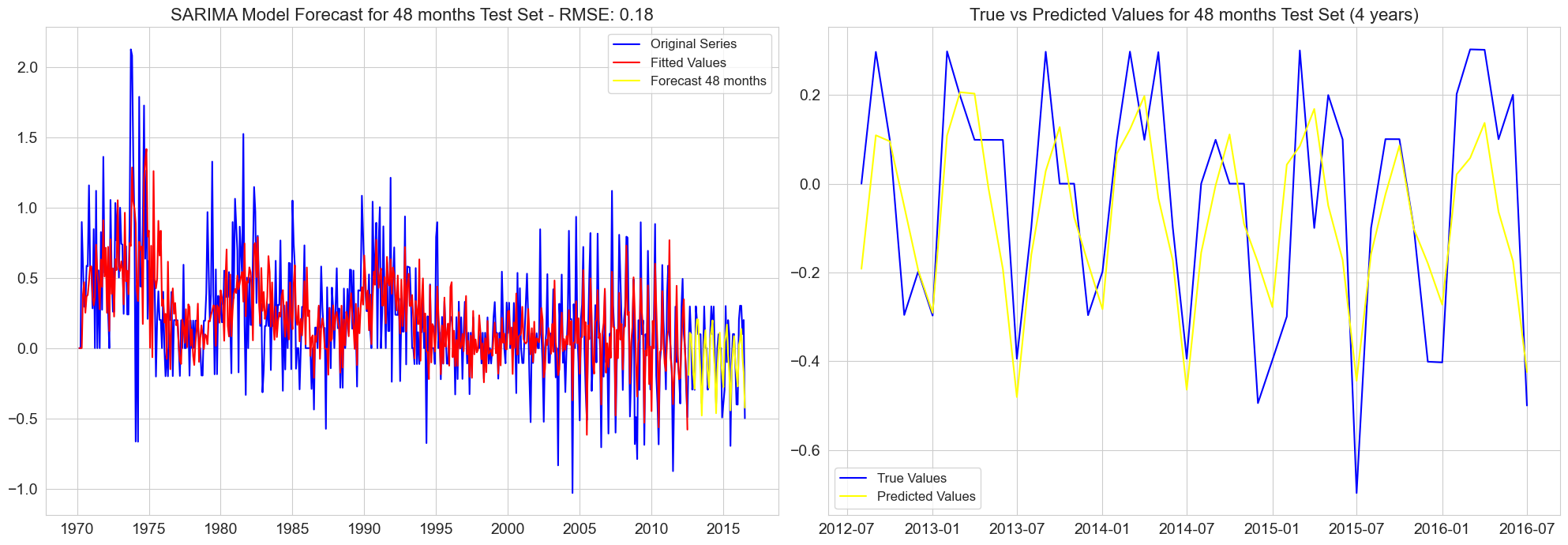
RMSE for 54 months test set: 0.17
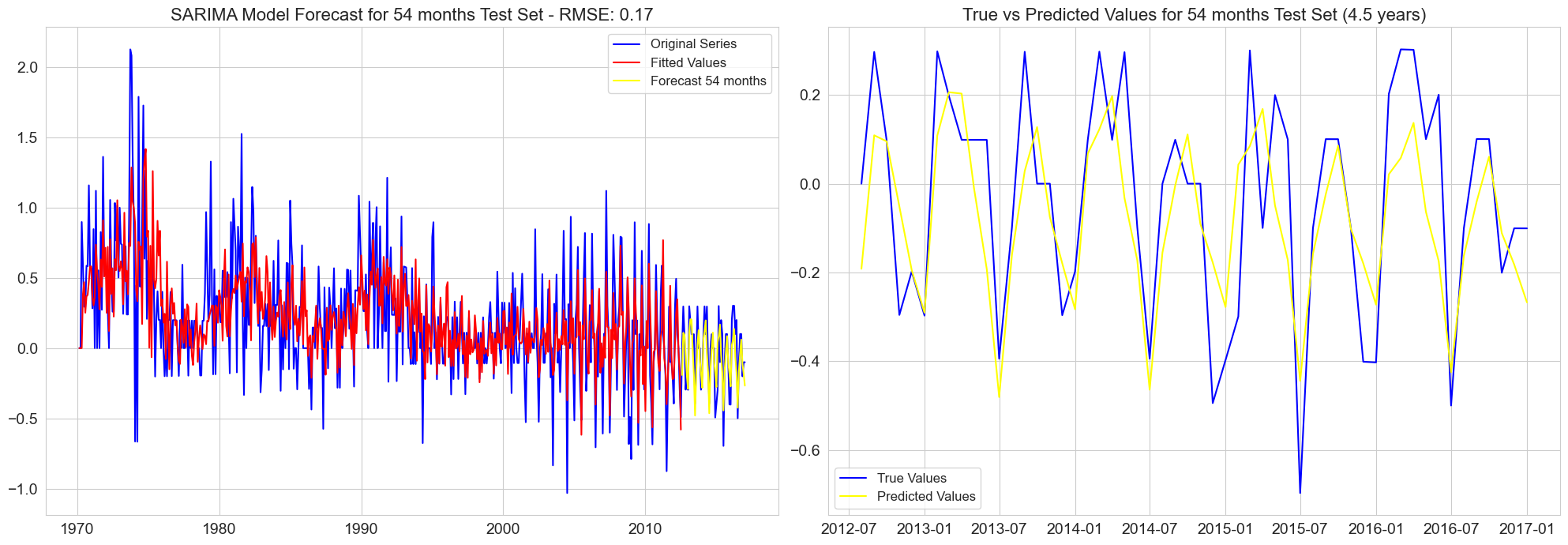
RMSE for 60 months test set: 0.18
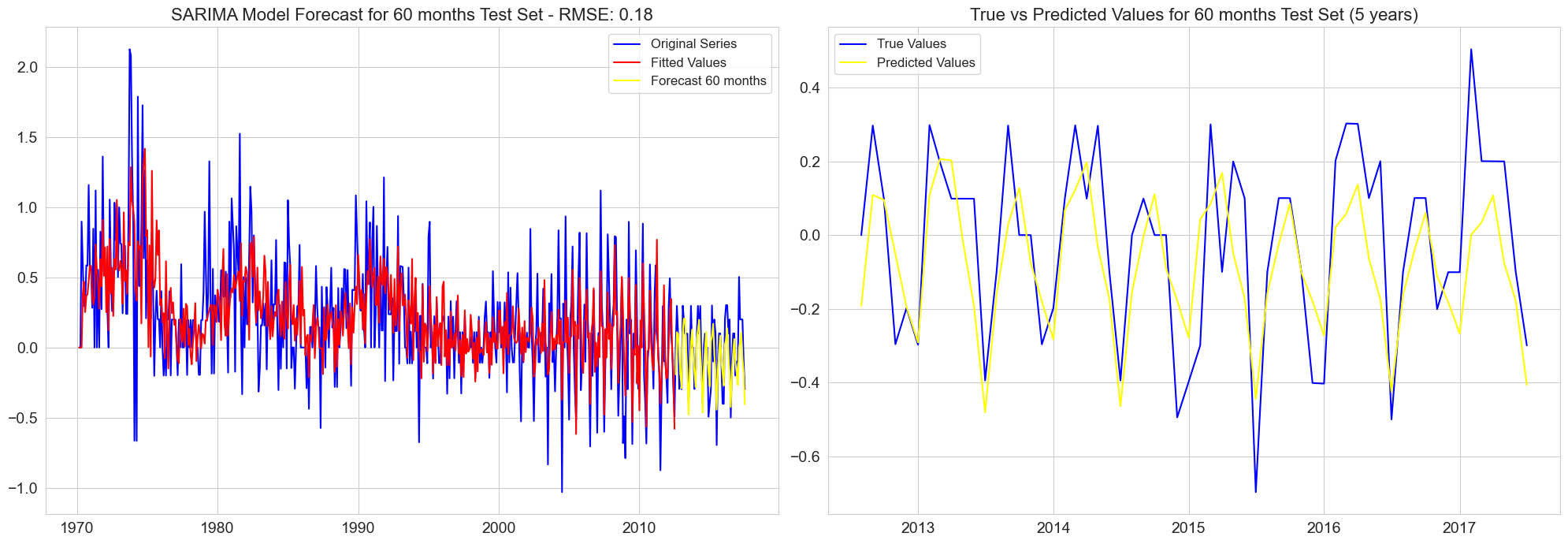
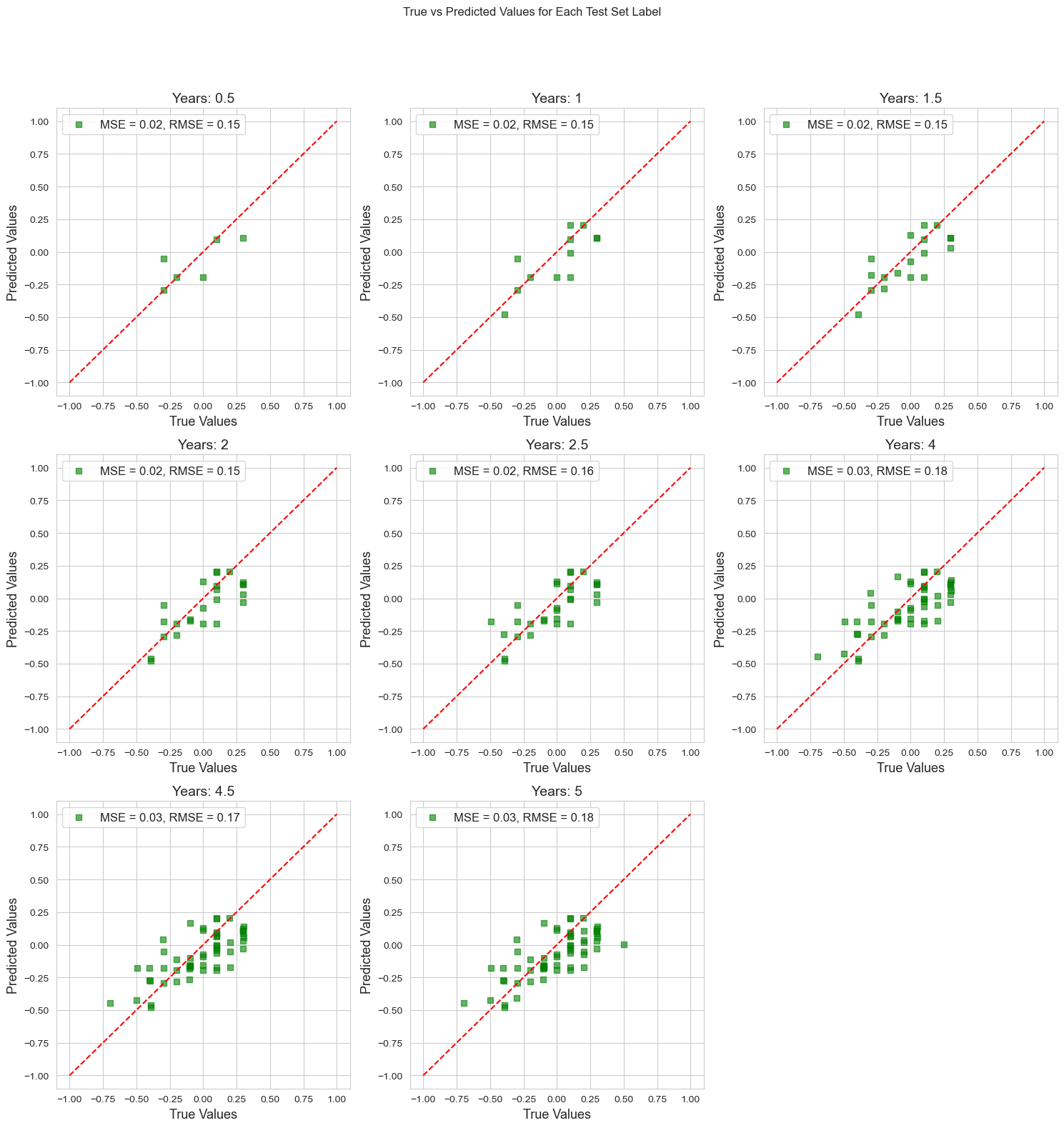
final_results = pd.concat(results, axis=0)
final_results.reset_index(drop=True, inplace=True)
final_results.set_index("Date",inplace=True)
unique_labels = final_results['Years'].unique()
n_labels = len(unique_labels)
n_rows = int(np.ceil(n_labels / 3))
fig, axes = plt.subplots(n_rows, 3, figsize=(15, 5 * n_rows))
fig.suptitle('True vs Predicted Values for Each Test Set Label', y=1.05)
if n_rows == 1:
axes = np.reshape(axes, (1, -1))
for i, label in enumerate(unique_labels):
row, col = divmod(i, 3)
ax = axes[row, col]
subset = final_results[final_results['Years'] == label]
mse = mean_squared_error(subset['True Values'], subset['Predicted Values'])
rmse = np.sqrt(mse)
label_text = f'MSE = {mse:.2f}, RMSE = {rmse:.2f}'
ax.scatter(subset['True Values'], subset['Predicted Values'], color='green', alpha=0.6, label=label_text, marker='s')
ax.plot([-1, 1], [-1, 1], color='red', linestyle='--')
ax.legend(loc='upper left', fontsize=12)
ax.set_title(f"Years: {label}", fontsize=14)
ax.set_xlabel('True Values', fontsize=13)
ax.set_ylabel('Predicted Values', fontsize=13)
ax.grid(True)
for j in range(i+1, 3 * n_rows):
row, col = divmod(j, 3)
fig.delaxes(axes[row, col])
plt.tight_layout()
plt.show()